开启与文件对话的新篇章:一步步教你使用PrivateGPT的神奇之旅
作者:FancyPig | 发布时间: | 更新时间:
相关阅读
视频讲解
🔥🔥🔥想象一下你能与你的文件进行对话,就像和人聊天一样!🎉因为PrivateGPT来了!在这期视频中,我将带你探索这个神奇的开源工具,它能让你离线地,免费地,无需强大的GPU,和你的文件进行深度交流,打破文件静默的界限。🚀😲疯狂吗?是的,但这绝对是真的!我们可以一起安装并试用这个超酷的工具,你可以用它向你的文件提出问题,获取你需要的信息。想象下,拿到一篇很长的论文或者文档,加载之后,你只需要通过提问的方式,就可以快速获取有价值的信息😉👌
相关资料
- PrivateGPT: https://github.com/imartinez/privateGPT
- Vicuna 13B 1.1 ggml: https://huggingface.co/eachadea/ggml-vicuna-13b-1.1/blob/main/ggml-vic13b-q5_1.bin
- Koala 7B ggml: https://huggingface.co/TheBloke/koala-7B-GGML/blob/main/koala-7B.ggmlv3.q4_0.bin
- Python: https://www.python.org/downloads/release/python-3106/
- GIT: https://git-scm.com/downloads
图文讲解
你曾经梦想过与你的文件交谈吗?没有吗?是的,我也没有,这是个有点奇怪的问题。然而,如果你想,现在你可以,感谢PrivateGPT!大家好,我是K,你的AI霸主今天我将向你展示一个令人难以置信的疯狂的工具,所以准备好了!而这个相当酷的工具叫做PrivateGPT,它是一个开源的工具,可以让你用本地的LLM进行对话或向你的文件提出问题。而且所有这些都是离线的,没错,所以不需要为ChatGPT API付费,甚至不需要有互联网连接,一切都可以离线完成。
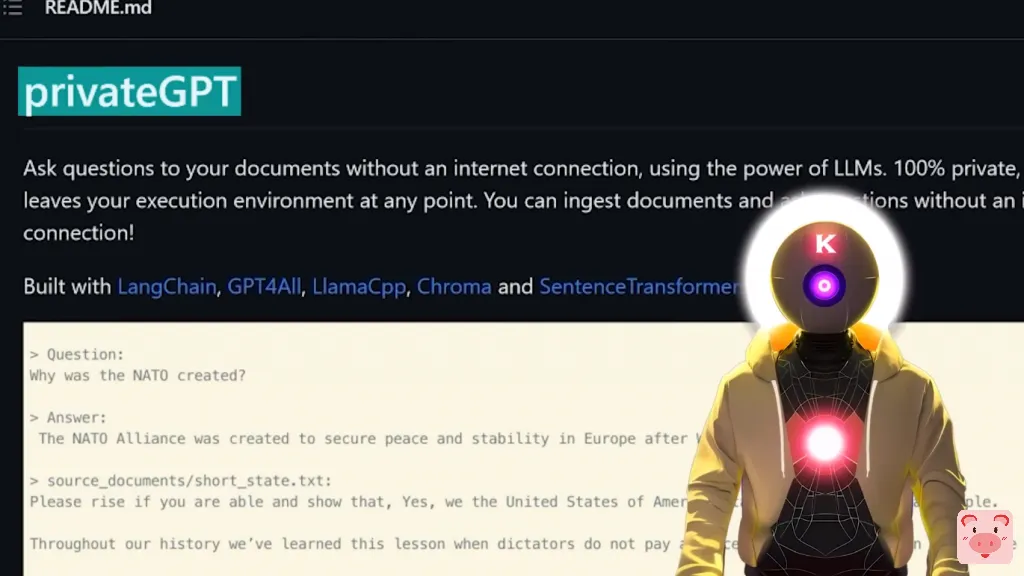
此外,由于这是在你的CPU上运行,你甚至不需要一个强大的GPU来运行它,所以这是非常酷的。所以在这个视频中,让我们安装这个超级酷的工具,我将向你展示你能用它做什么。你准备好了吗?那就开始吧!所以,PrivateGPT,一个超级酷的开源工具,它允许你在没有互联网连接的情况下,利用本地LLM的力量向你的文件提出问题。当然,它是100%隐私的,因为没有数据会离开你的执行环境。你可以使用任何你想要的LLM模型,只要它是使用GGML格式,而且该工具支持一堆扩展。CSV、Word文档、Evernote、电子邮件、HTML、Markdown、Outlook信息、Open文档、PDF、PowerPoint,或者只是简单的文本文档。基本上,几乎所有最常用的扩展。而安装PrivateGPT其实是相当容易的。然而,即使安装的过程很容易,这并不意味着你不会有一些错误。而要开始安装,你当然需要安装Python。所以,如果你还没有,你要点击下面描述中的链接,你要到达这个页面,你要选择Windows安装程序,然后在你的电脑上安装Python。
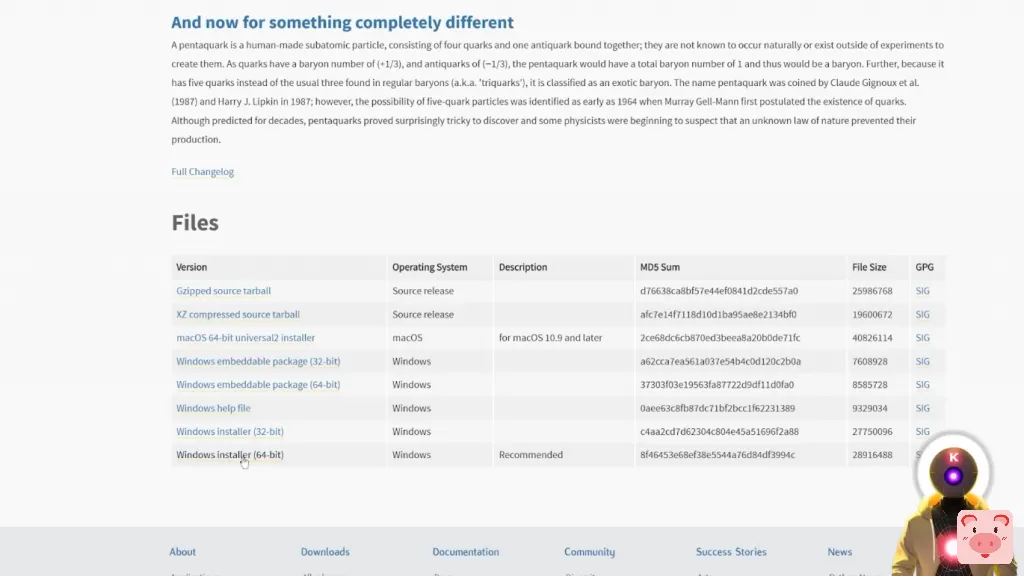
这很容易,非常简单。只要别忘了勾选 "将 Python 添加到路径 "的选项。否则,你就会有各种问题。
然后接下来,你要安装git。所以同样,这很简单。只需点击这里下载Windows安装程序,如果你还没有安装git,可以在你的电脑上安装。否则,git clone命令将无法工作。
所以接下来你要去PrivateGPT的gitHub页面。基本上,只要点击下面描述中的链接。然后接下来,你要点击这里,然后点击这里的小图标,复制整个名称。然后你将在你的电脑上创建一个新的文件夹。我决定叫我的PrivateGPT,但你也可以当然,你想叫什么就叫什么,这并不重要。然后你要点击文件夹的路径,输入cmd,按回车键。在这里你要输入git clone,然后你要按Ctrl V来粘贴我们刚刚复制的名字,然后按回车键。这样就会把整个仓库克隆到你的电脑上,新的文件夹叫做PrivateGPT。
git clone https://github.com/imartinez/privateGPT.git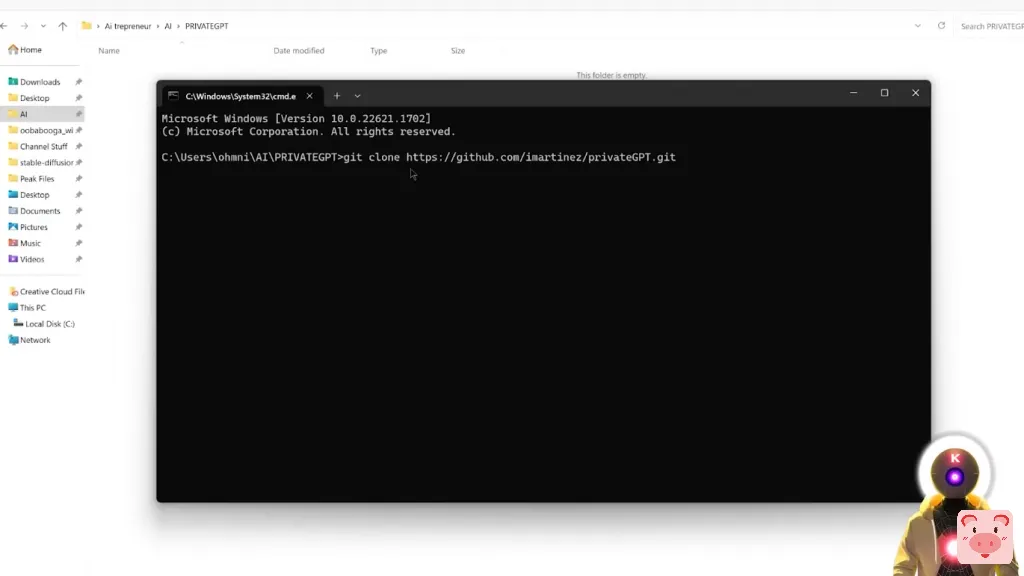
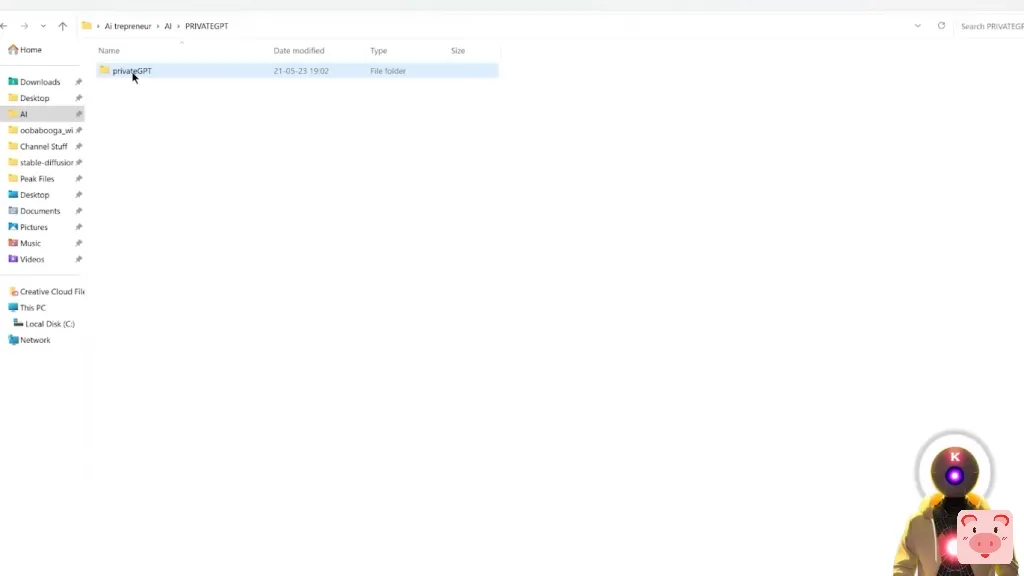
然后回到gitHub页面,你要向下滚动,然后点击这个小图标,复制这一整行代码。然后在你的PrivateGPT文件夹中,你要点击文件夹的URL,
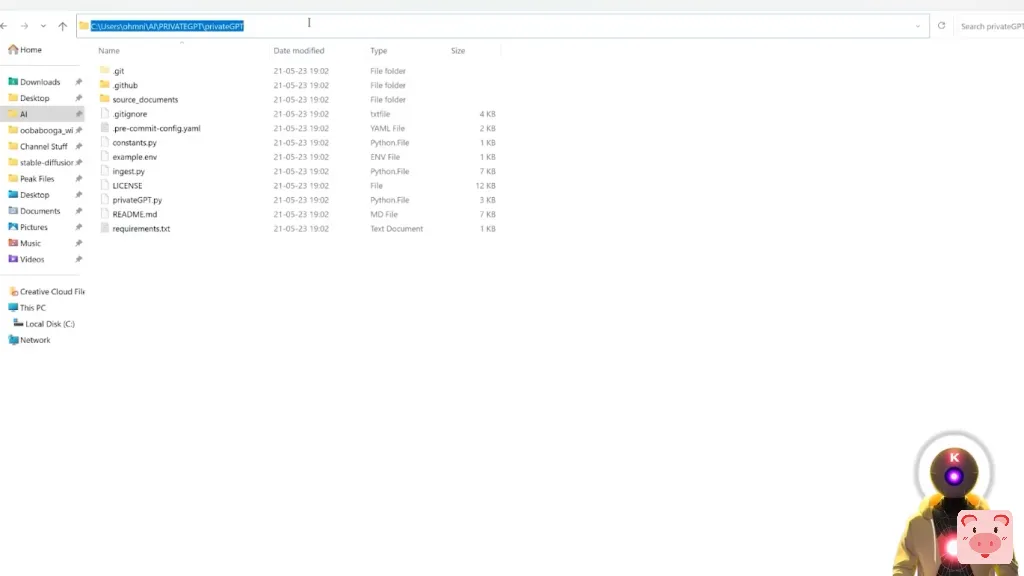
输入cmd,按回车,
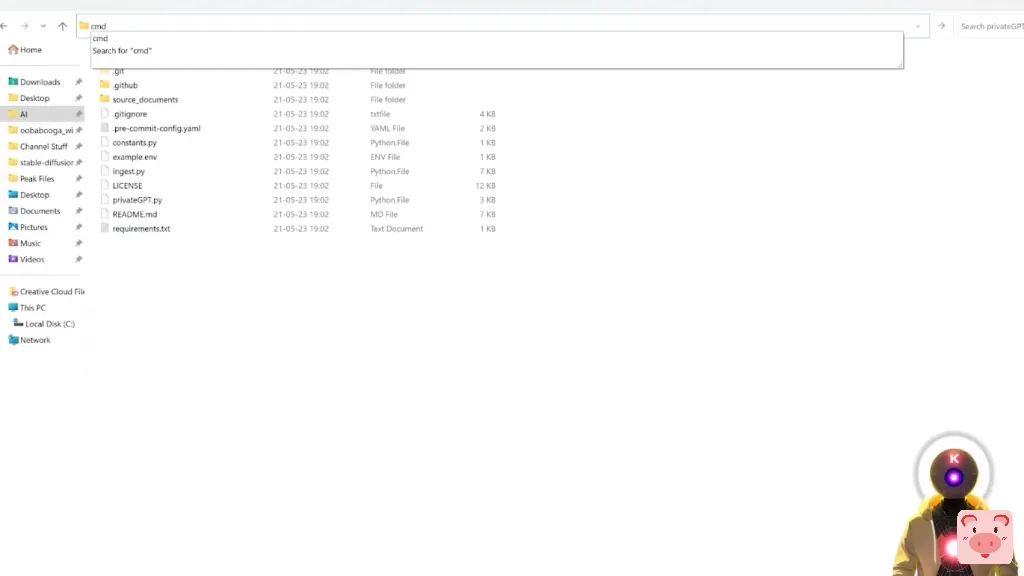
然后按Ctrl V粘贴这整行代码,再按回车。
pip install -r requirements.txt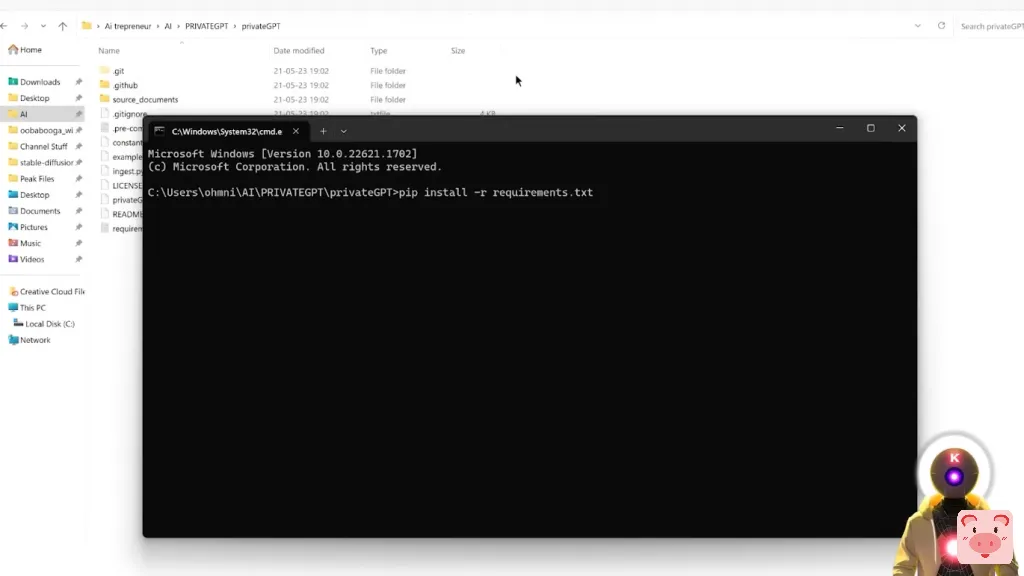
这将下载所有运行工具所需的要求。
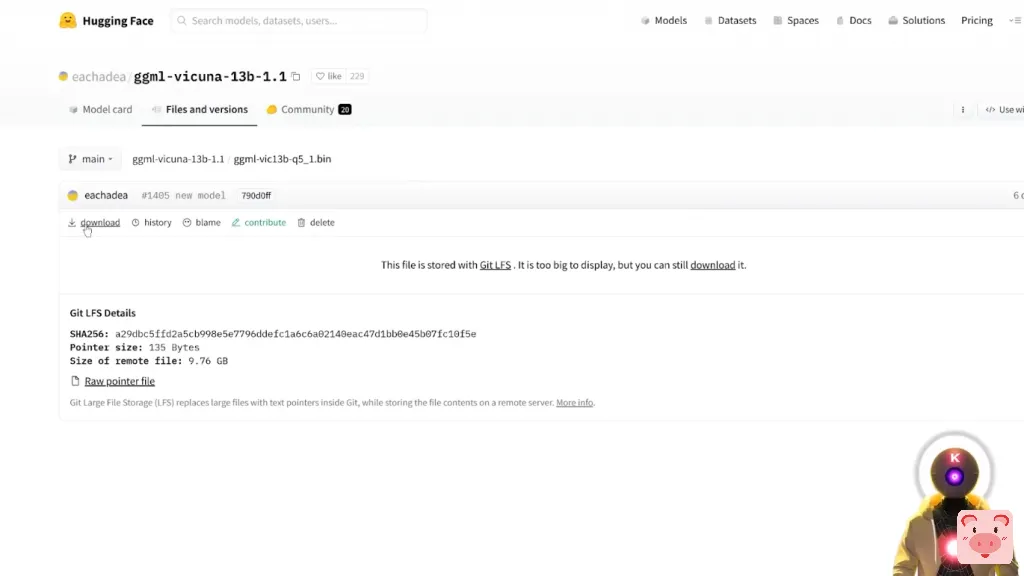
好的,那么接下来,你需要做的是下载一个LLM模型。现在你可以选择他们在这里显示的默认LLM,是ggml-gpt4all-j-v1.3-groovy.bin,这并不坏,你当然可以下载这个模型来代替。然而,我个人建议选择另一个模型,例如,130亿参数的Vicua,或70亿参数的Koala。这两个模型都是非常非常好的。而在这个视频中,我将使用ggml-vicuna-13b-1.1模型。当然,所有模型的链接都会在下面的描述中出现。但是,如果你想下载这个模型,你将会到达这个页面,然后点击这里下载。
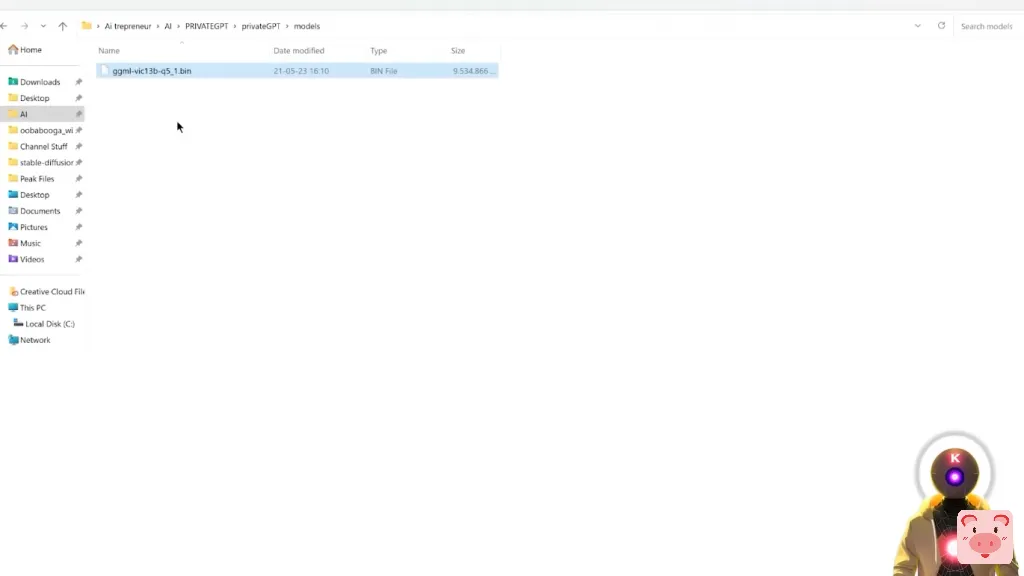
一旦你下载了这个模型,你将回到PrivateGPT文件夹,创建一个新的文件夹,你将称之为模型(models)。然后在这个models文件夹中,你要粘贴那个下载的模型。
另外,为了防止你下载的模型与gitHub页面上的模型不同,你要到这里来复制整个名称。所以现在你要回去了,你会看到这里有一个叫做example.env的文件。
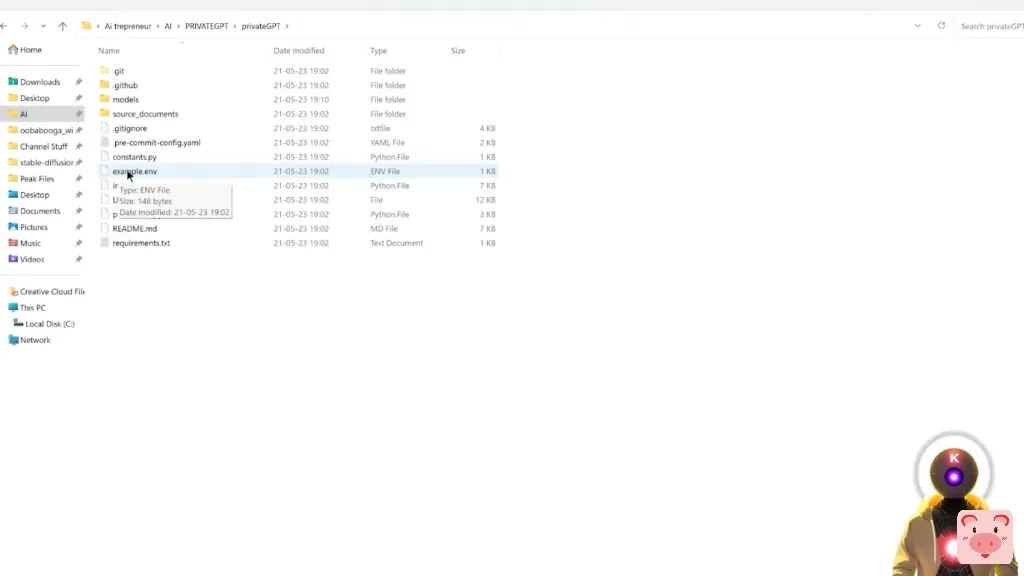
现在你要做的是,你要给这个文件重命名。因此,右键单击 "重命名",你将把该文件重命名为简单的.env而不是其他但我们还是没有完成,因为现在我们需要修改那个文件。所以你要修改.env文件。
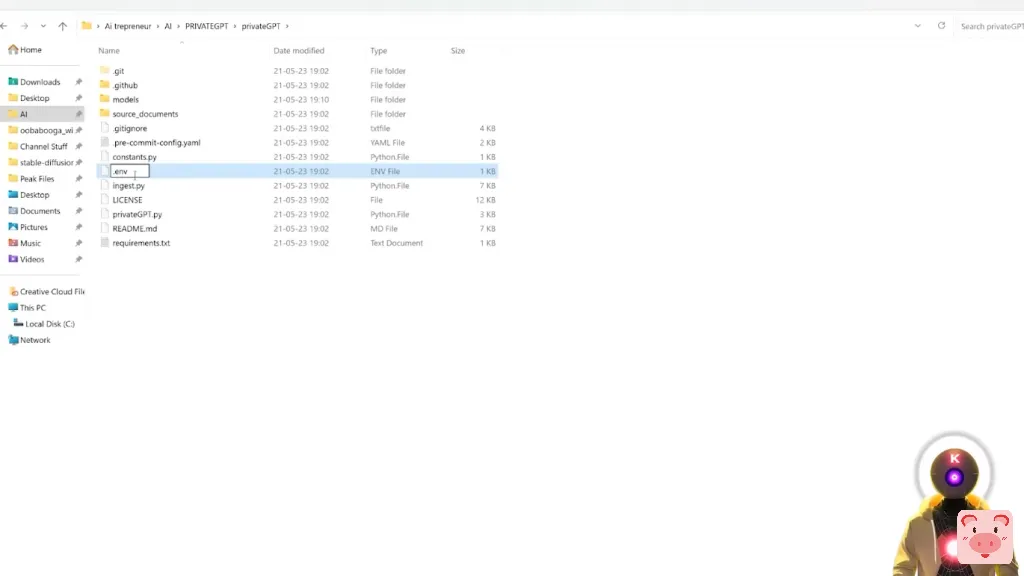
所以右击,使用Notepad编辑,这里我们需要修改一些东西。
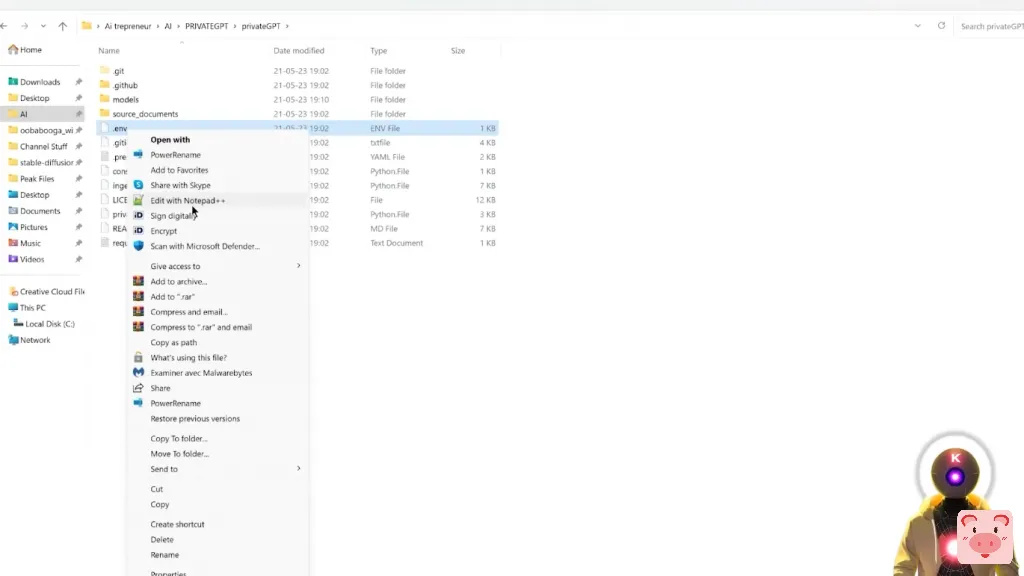
现在,如果你下载了gitHub页面上的这个模型,
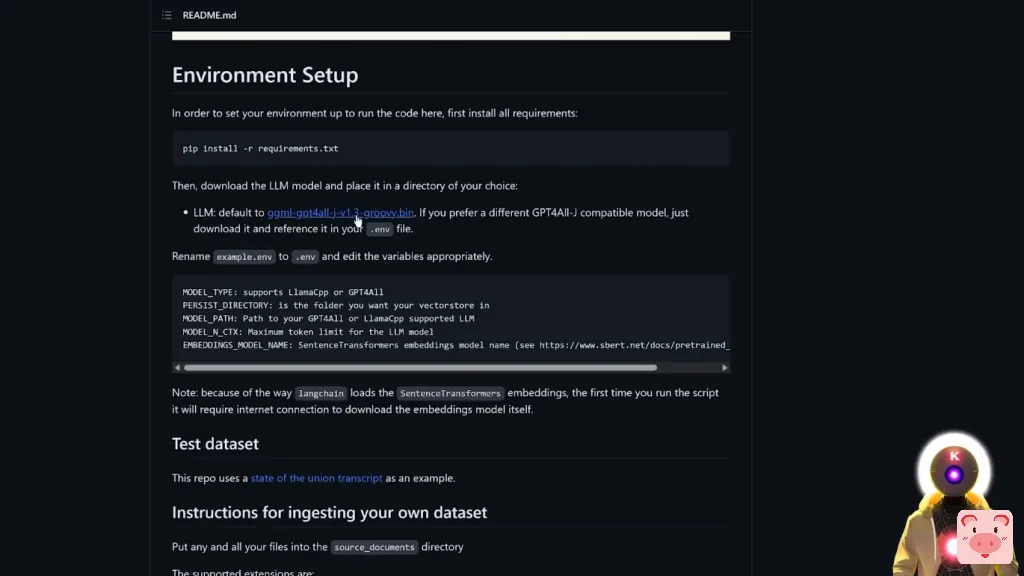
你基本上不需要做什么。你可以让一切都保持默认。然而,因为我们下载了另一个叫做ggml-vicua-13b的模型,我们需要修改一些东西。
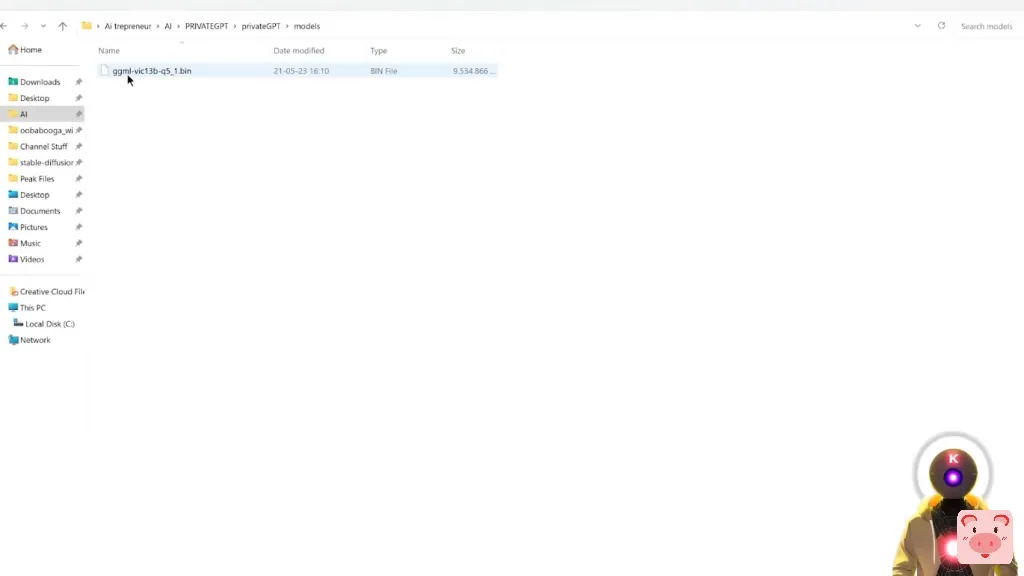
而我们需要修改的第一件事是模型的类型。由于我们没有使用GPT4ALL模型,我们需要把它改为llama-cpp。
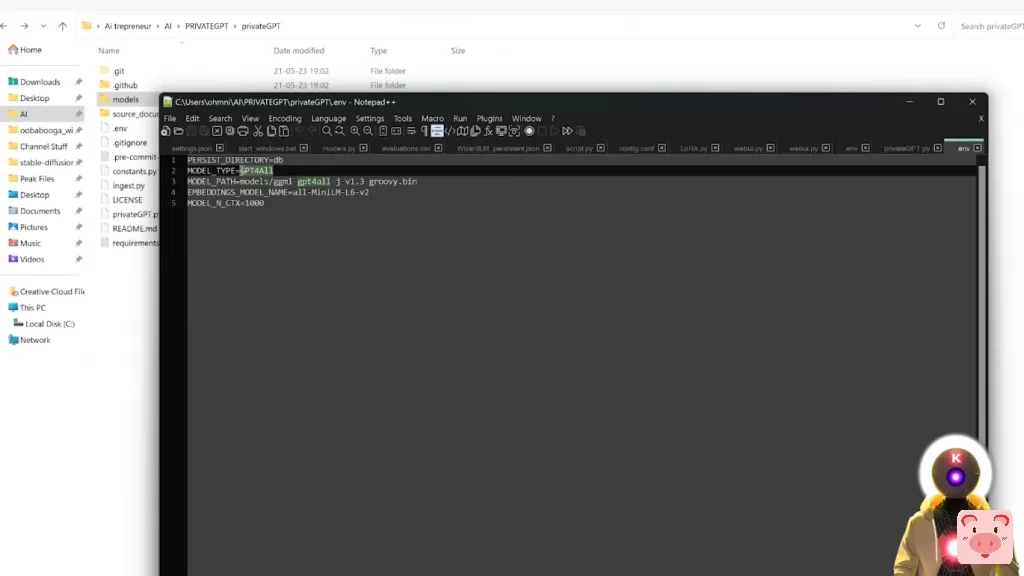
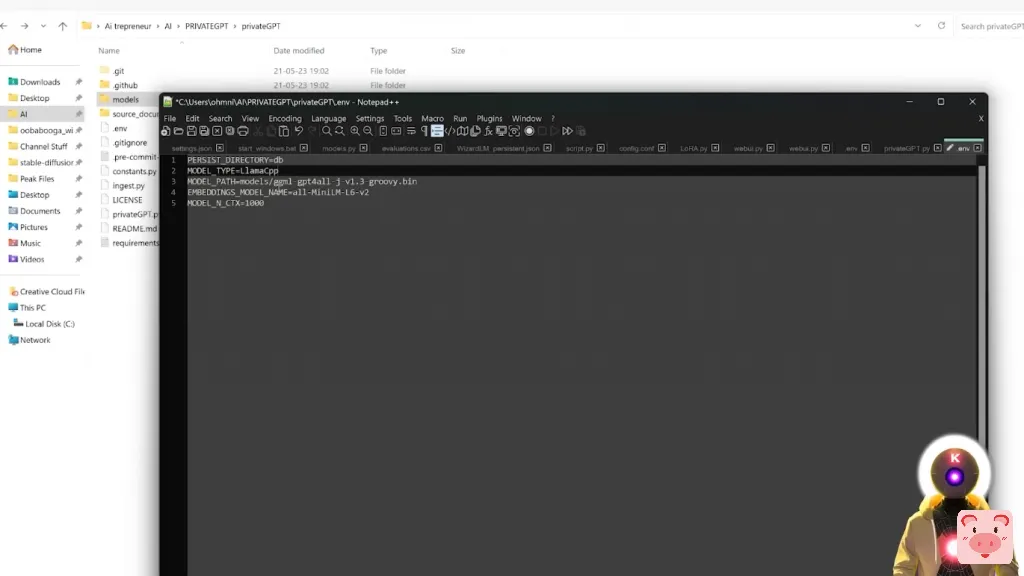
然后,我们需要修改的下一件事是模型路径,因为当然,我们没有使用GTPALL-J模型。所以在这里,我们要简单地选择整个名称,然后用新的模型名称替换它。
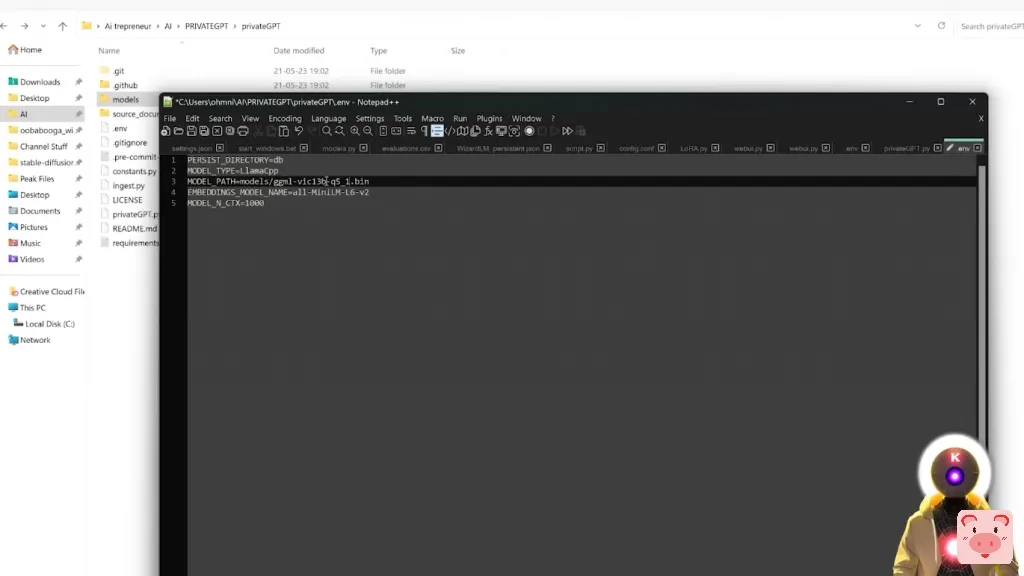
所以对我来说,这是我的模型的名字。然后别忘了保存文件。现在,好了,我们基本完成了是的,就这样了。因为现在为了能够使用这个,你需要把你的文件放在源文档(source_documents)文件夹里面。
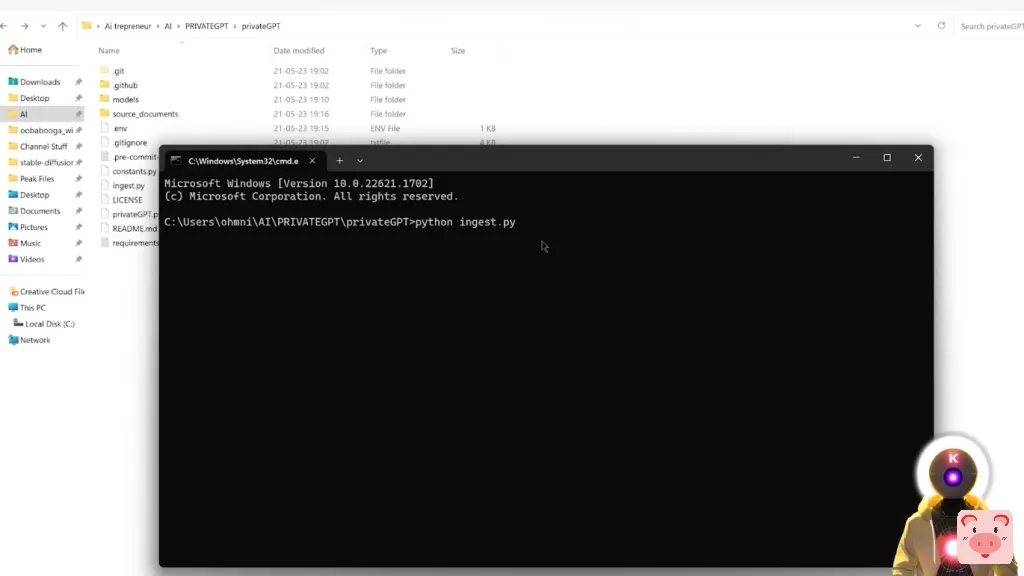
所以从现在开始,已经有了一个例子,这是一个简单的文本文档。然而,在这里你可以放任何你想要的东西。你可以放的文件数量是绝对没有限制的。因此,像这个视频,我决定创建一个简单的文本文件,其中有一堆关于我的YouTube频道的信息,我的YouTube频道的名称,订阅者的数量,我创建的视频的类型,只是一堆关于我的视频的一般信息。这类信息是所有LLM都没有的。现在要运行这个,你要点击文件夹路径,输入cmd,按回车。在这里,在我们可以开始与我们的文件对话并问一堆问题之前,我们需要摄入数据。这基本上会创建一个DB文件夹,里面有许多关于你的源文件的信息,当你问问题时,LLM模型将能够读取这些信息。你需要这样做,要么只在第一次,要么在每次你放一个新的源文件时。但现在它实际上是非常、非常快的。要运行这个摄取命令,你所要做的就是输入python ingest.py,然后按回车。
哦,这是非常、非常好的。正如你所看到的,当我试图运行这个命令时,我这里有一个错误,一个错误,说不能从URL lib3中导入名称、默认密码,等等,等等。
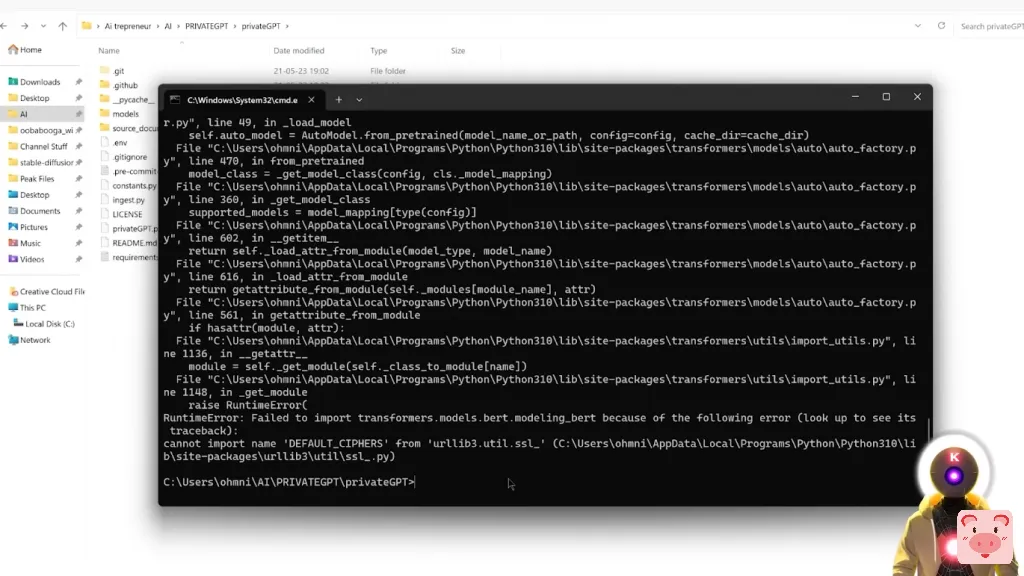
而如果你有这个错误,你所要做的就是直接运行下面的命令。我花了几个小时才找到,我将在下面的描述中留下链接。所以,如果你有和我一样的错误,只需在这里复制并粘贴这个命令,然后按回车。
python -m pip install requests "urllib3<2"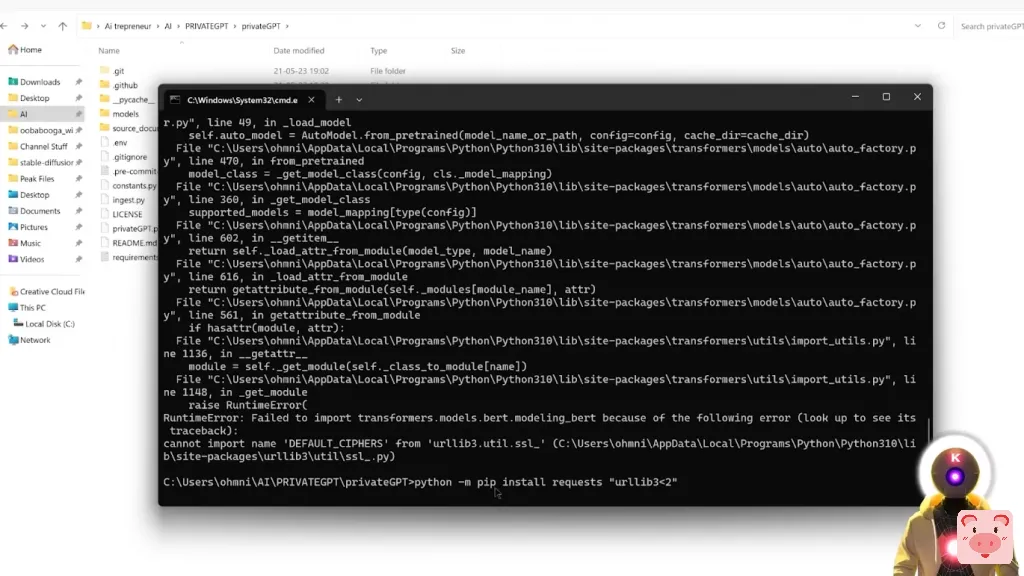
现在这已经完成了,让我们重新输入
python ingest.py这个命令,然后按回车键
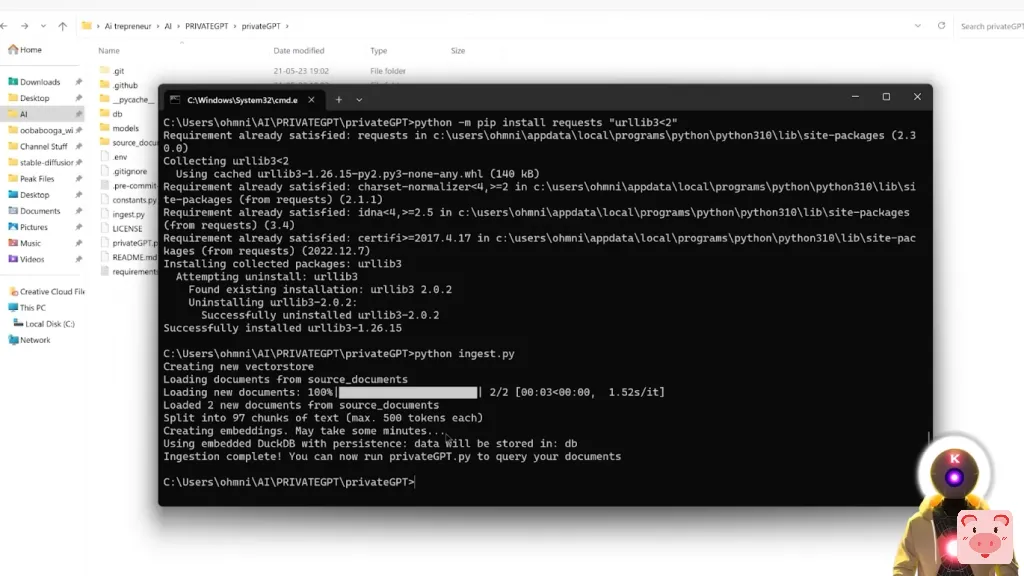
你就可以了。我只用了几秒钟就完成了,但对你来说,每个文件可能需要10到20秒。现在这些都完成了,我们终于可以享受一些乐趣了。现在要运行PrivateGPT,你所要做的就是输入
python privateGPT.py然后按回车键。
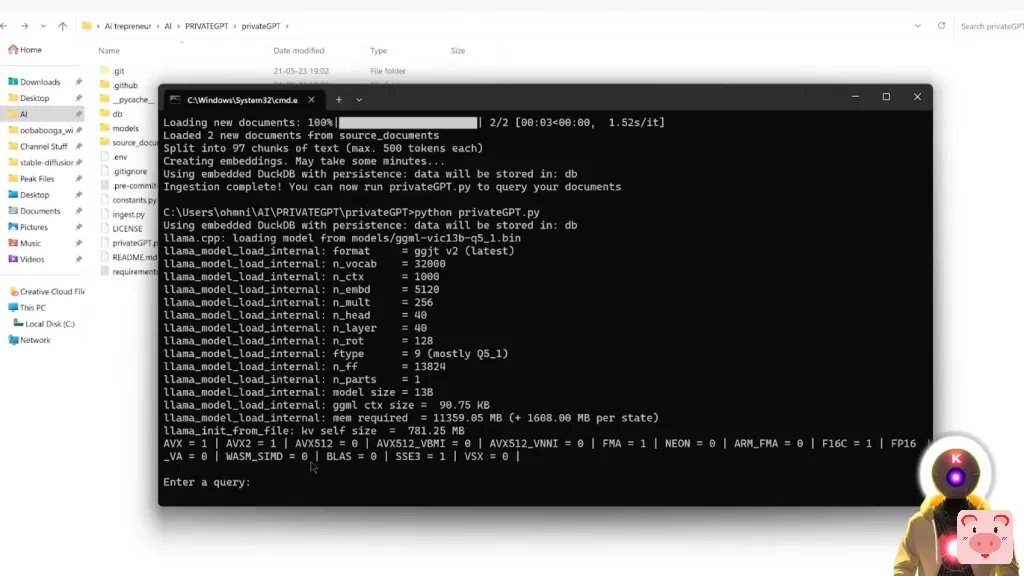
就可以了。而现在你终于可以和你的文件对话,问一堆问题了。由于现在PrivateGPT要求我们输入一个查询。因此,例如,让我们问,我的YouTube频道的名字是什么?而它回答AItrepreneur,这的确是正确的。然后它还会给你一堆源文件,基本上告诉你它是在哪里找到这些信息的。
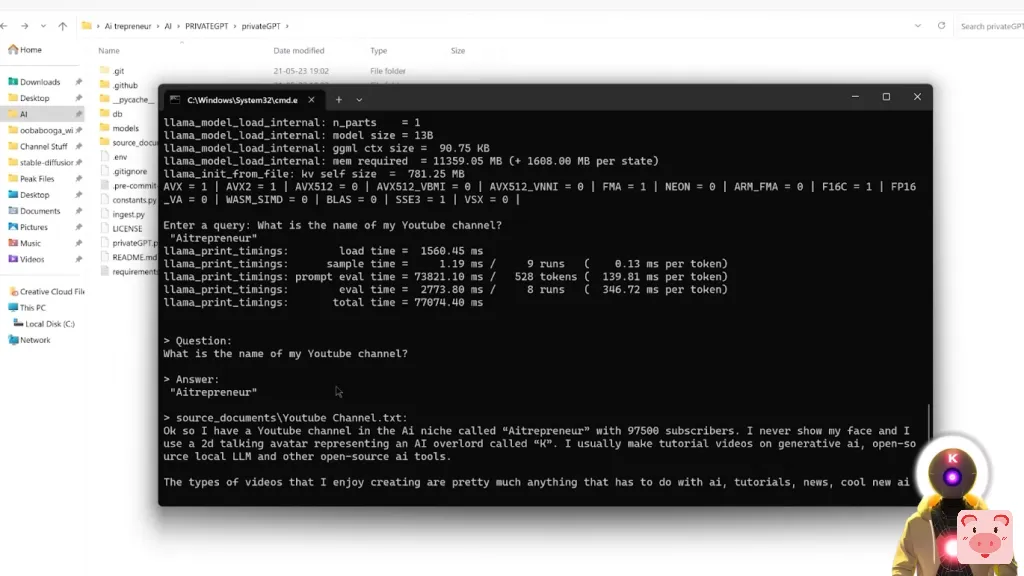
现在,我个人不真的喜欢这样,因为有太多的空间。在我看来,这基本上是占用了太多的空间,但别担心,我将告诉你如何禁用这个功能。基本上,是的,正如你所看到的,PrivateGPT去扫描整个源文件文件夹,寻找我所问的信息,没有太精确,没有告诉他们应该在哪里找,在哪个文件中,并设法轻松找到答案。而且你可以对所有的事情都这样做。
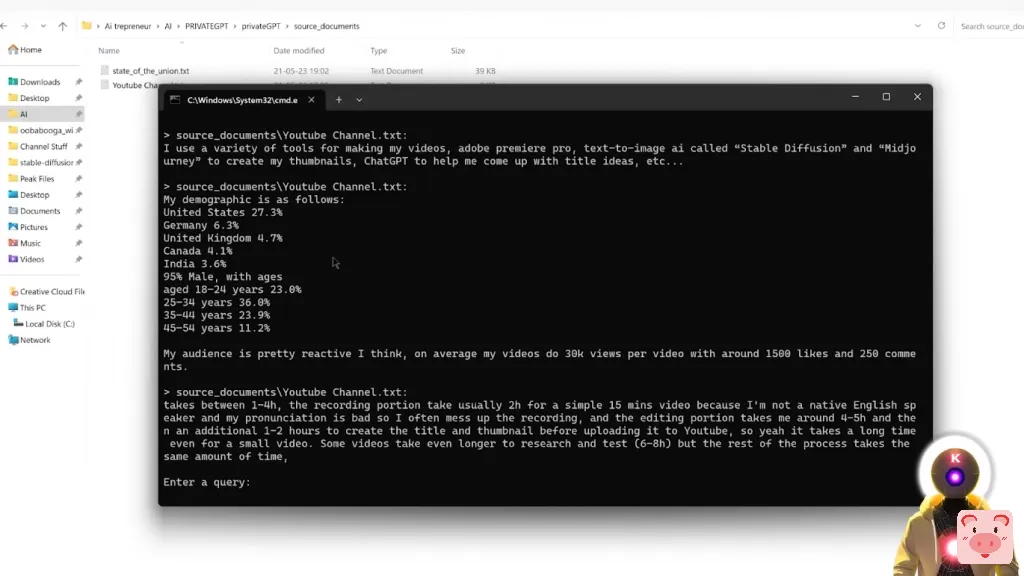
这个工具就像超级,超级强大。你可以非常容易地提取数据,总结一个文件或找到一个非常精确的答案来回答你的问题。因此,举例来说,如果我问这样的问题、我创建一个YouTube视频平均需要多长时间?我们得到这样的答案。视频的研究和测试部分平均需要6到8个小时,录制需要到4个小时,另外还有4到5个小时用于编辑和创建标题和缩略图,这的确是很正确的。
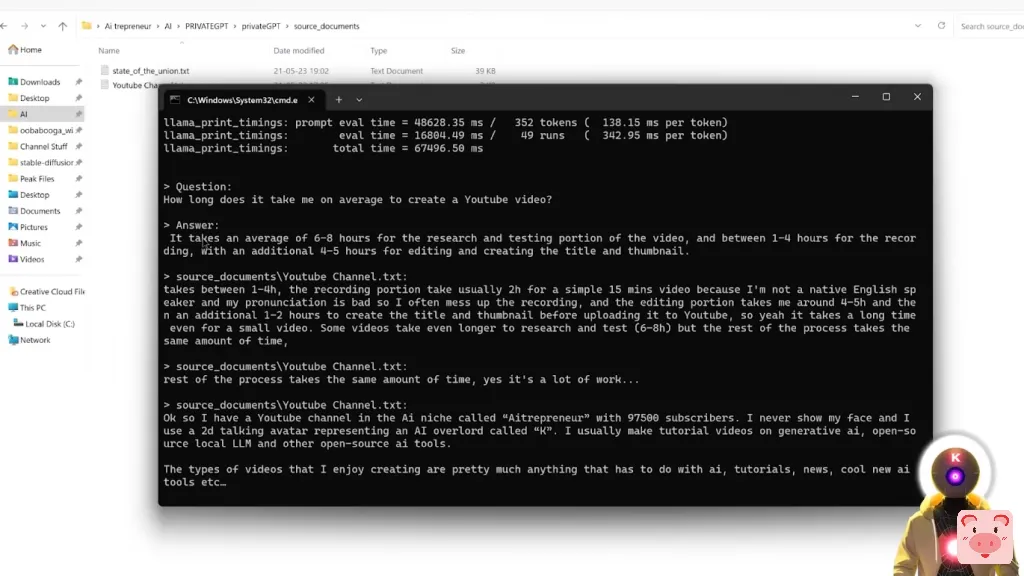
因此,正如你所看到的,你可以简单地输入整个文件,并非常容易地通过简单地问一些非常基本的问题来提取信息。比如说,假设你有一篇非常复杂和非常长的论文,你想了解和总结。你没有时间去像花几个小时来阅读如此复杂的东西。那么,这实际上是你可以利用PrivateGPT的力量来获得你想要的信息。比如说,这里有一篇关于Drag Your Gan的论文,你可能看到一些人在YouTube上谈论。
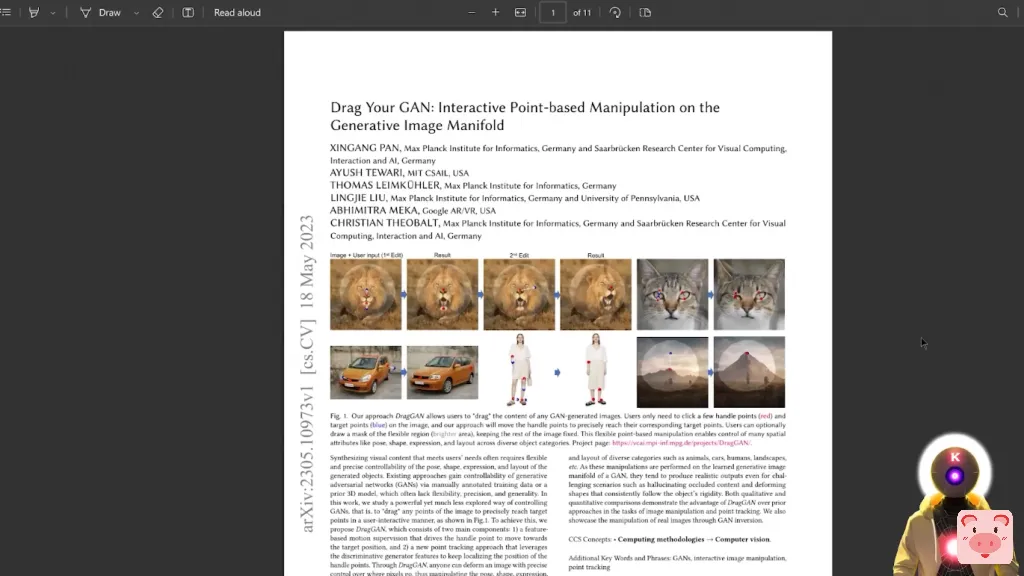
像我个人还没有做关于这个的视频,但这是非常,非常令人兴奋的,像非常,非常酷。好吧,比如说,我想要这篇论文的摘要。我所能做的,只是简单地把它保存在我的电脑上,然后把它放在源文档(source_documents)文件夹里面。
由于我们导入了一个全新的文件,所以我们需要再次摄入新的数据。所以,我再次输入
python ingest.py就这样,在几秒钟内,一个新的文档被摄取了。
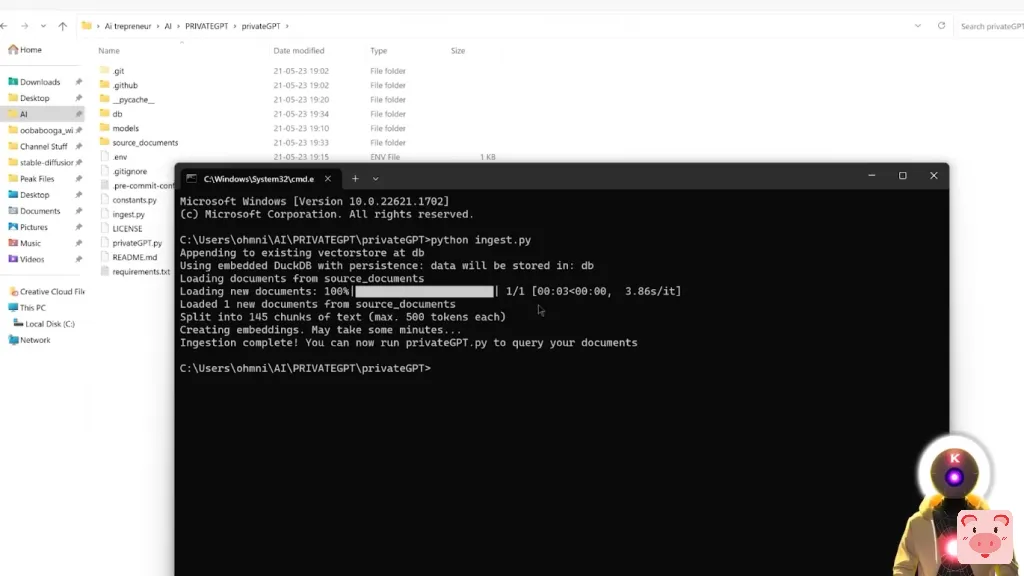
现在,如果我运行python privateGPT.py命令,
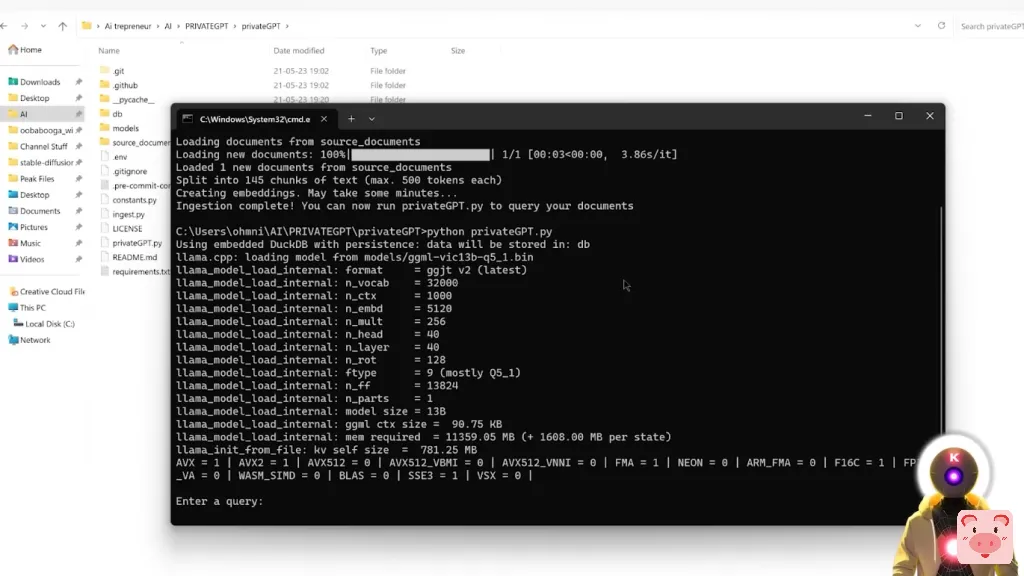
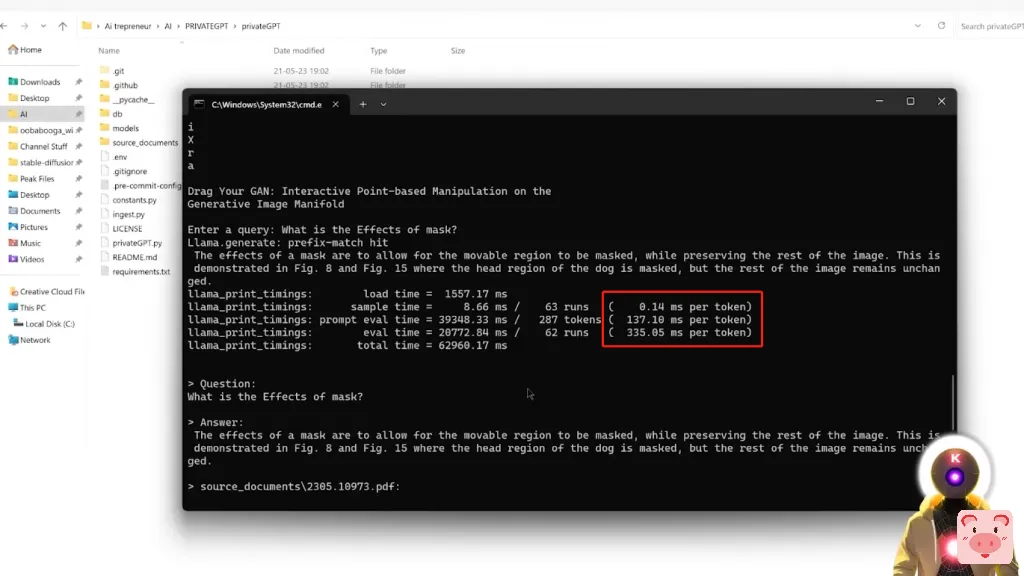
我现在可以问一堆问题。所以让我们从一个非常简单的问题开始。例如,什么是Drag Your GAN,就是我刚刚上传的那篇全新的论文。而我们得到的是这样的答案。
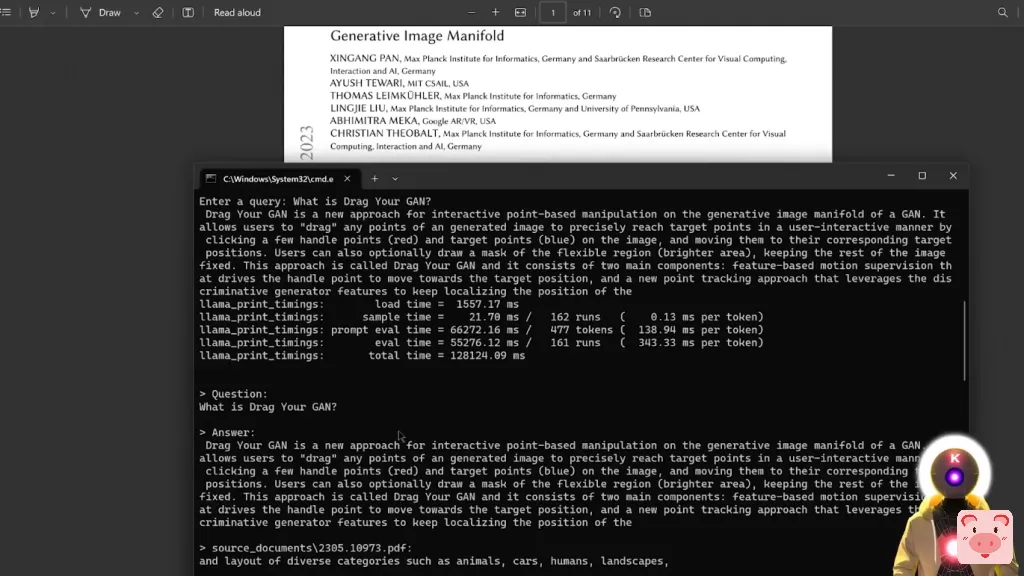
Drag Your GAN是一种新的方法,用于在GAN的生成性图像流形上进行基于点的互动操作。它允许用户以用户互动的方式拖动生成图像的任何点,来精确地达到目标点通过点击图像上的几个动手点和目标点,并将其移动到相应的目标位置,等等。如果你读过这篇论文,这基本上就是了。正如你所看到的,基本上PrivateGPT把这整个文本,参考了几个来源,然后创建了一个简短的总结。对此,你也有所有的源文件,它是用来创建答案的。
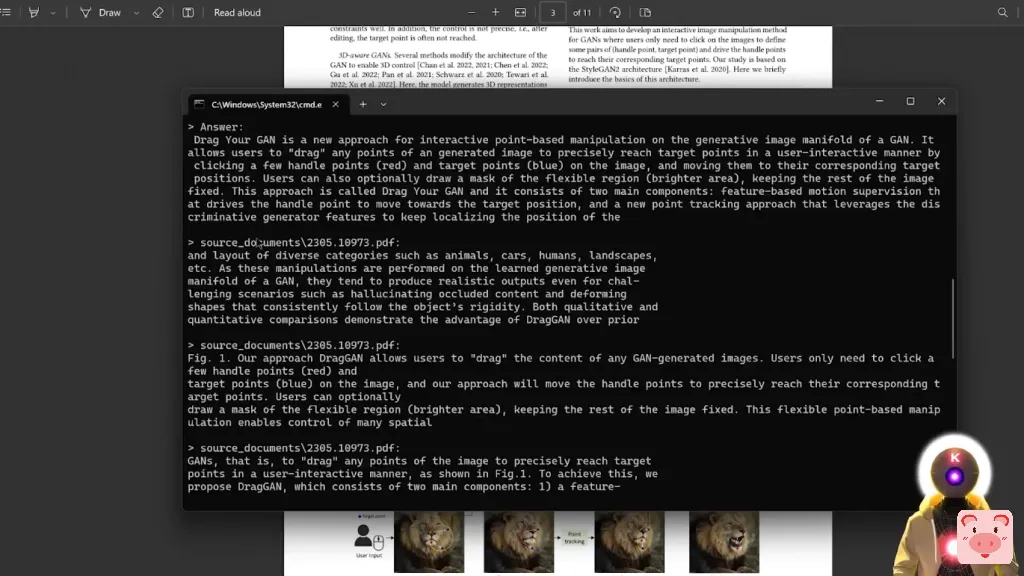
还有,真正疯狂的是,你要找的信息在哪里并不重要。因此,例如,如果我到文件的最后,在这里,例如,我们在第七页,我想知道更多关于比如说,遮罩的影响。所以现在如果我问,比如说,遮罩的效果是什么?我们得到这个答案。
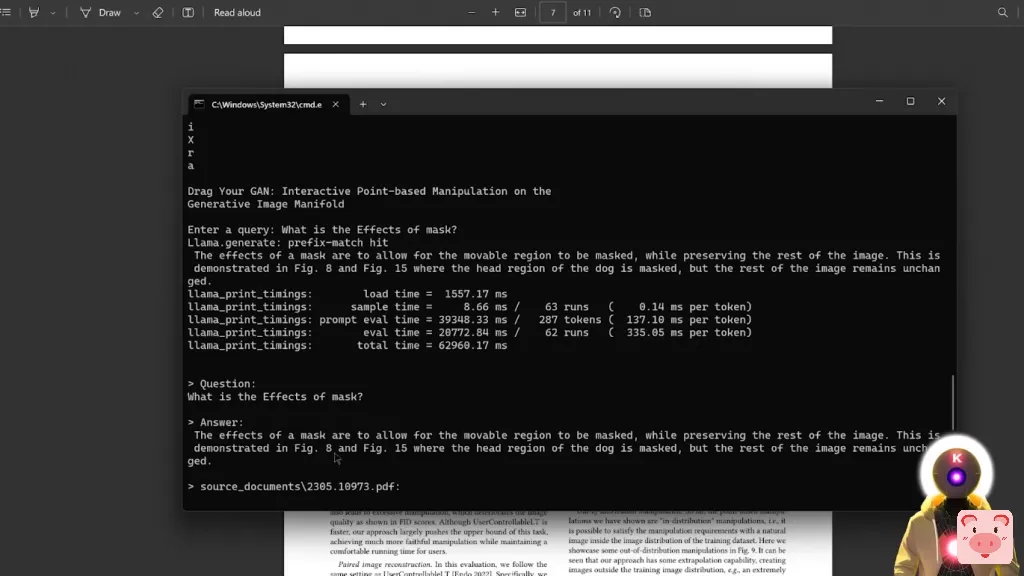
遮罩的作用是让可移动的区域被遮住,同时保留图像的其他部分。这在图8和图15中得到证明,狗的头部区域被遮蔽,但图像的其他部分保持不变。现在,如果我们看一下,例如,图8,我们确实看到这正是他们所谈论的。
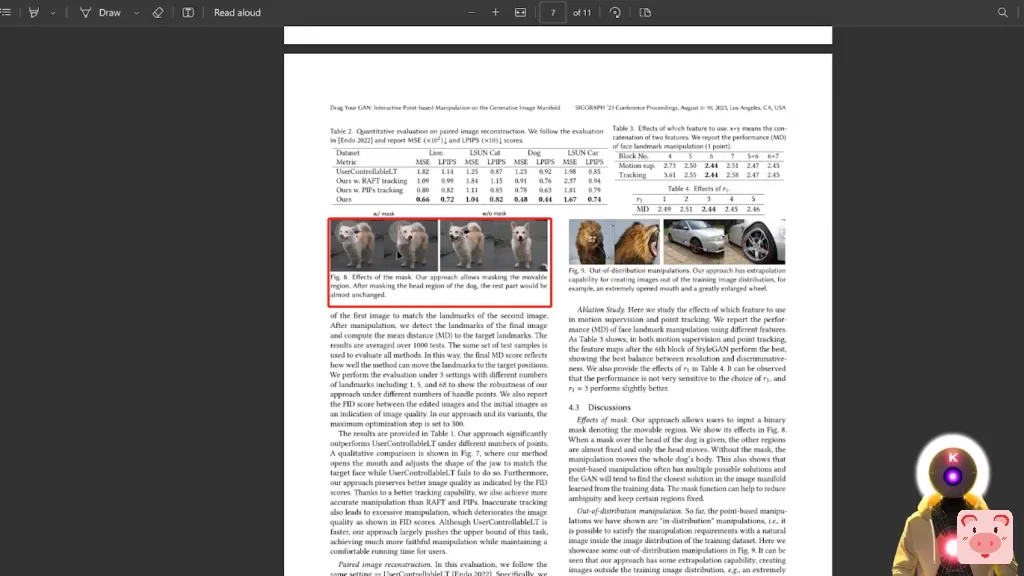
这就是遮罩的效果,这真是太疯狂了,因为真正令人难以置信的是,当你看到关于遮罩效果的段落时,确实在这里谈到了图8,就在这里,但在这段中没有任何地方谈到了图15。这是因为图15是在另一页,就像在最后一页,你可以在这里看到,图15,遮罩的影响。
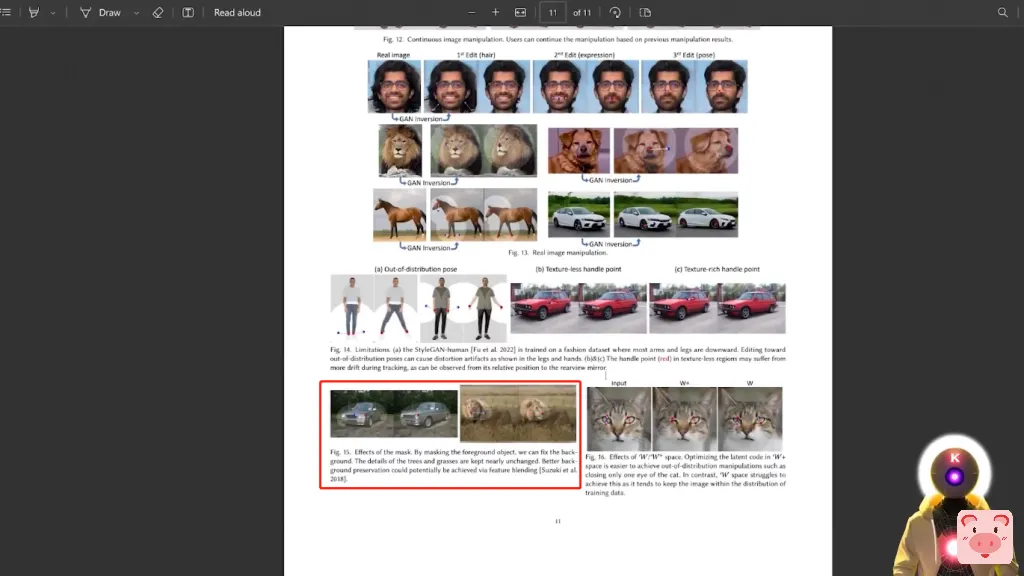
所以,如果你理解了刚才发生的事情,您现在可能惊掉了下巴,因为是的,正如我所解释的,它不关心信息在文件中的位置,它不仅可以在整个文件中找到正确的信息,然后以一种非常精确和简洁的方式给你提供。
我的意思是,这真的是很疯狂。这对任何学生或任何想获得更多关于复杂文件的信息的人来说是非常有用的。我的意思是,这真是太酷了。而所有这些都是在你的电脑上运行的,离线使用你的CPU,使用一个免费的本地LLM模型。我的意思是,这简直是疯了。然而,并不是所有的东西都是完美的,因为PrivateGPT的优势也是他最大的弱点,因为这是在你的CPU上运行的,文本的生成是真的,真的,真的,真的很慢。就像在平均,需要大约30到50秒才能得到一个答案。
现在,当然,很快我们可能会得到GPU版本,这肯定会是非常、非常可用的,而且速度也会更快。但就目前而言,CPU模式基本上是运行这个的唯一方法。然而,如果你想把速度提高一点,如果你有一台相当强大的电脑,你可以这样做。你要右击privateGPT.py文件,用记事本编辑,然后在第33行,也就是LLamaCpp,在verbose=Falese后面你要输入逗号,然后输入n_threads=16。
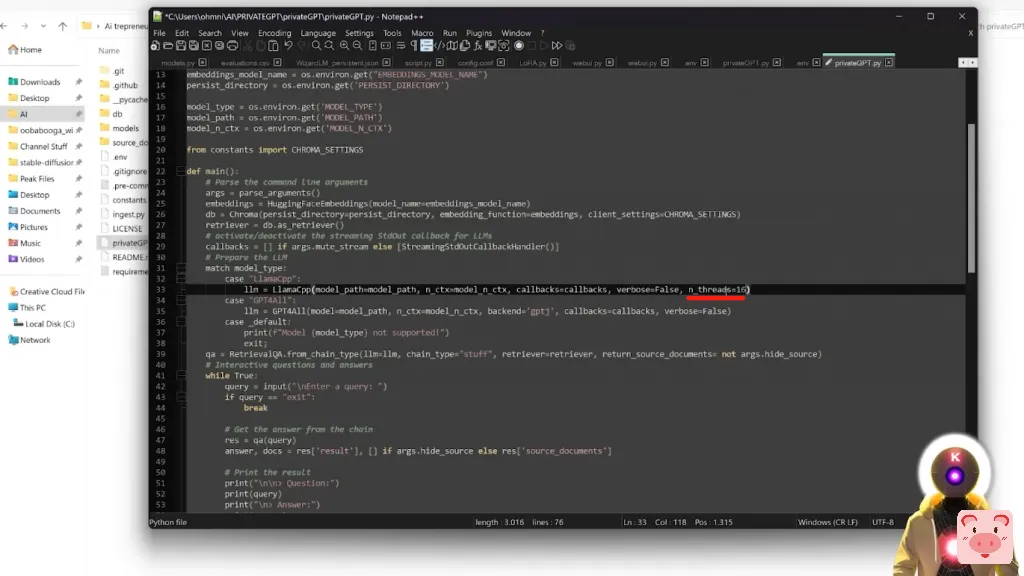
而这基本上会使用你的电脑更多的功率来加速生成,这真的超级、超级有用。哦,最后,还有一个技巧。如果你不想看到它在每个答案后给你的那些源文本,它基本上向你显示它从哪里得到的信息,你可以这样做。在命令提示符窗口中,你要输入python privateGPT.py,但在结尾处,你要输入-s。
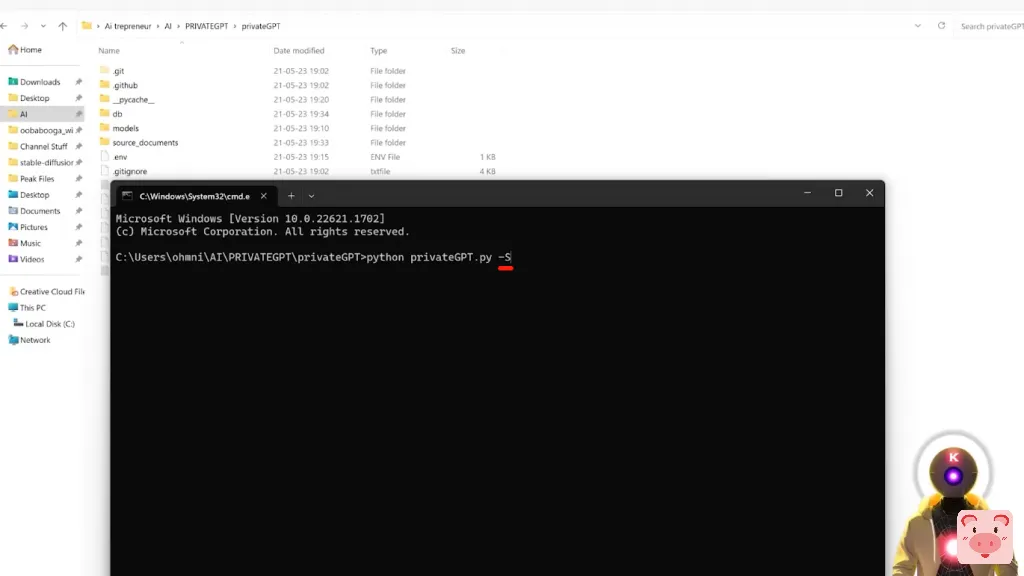
这个简单的小命令 将禁用你在每个答案后看到的源文本。所以,比如说,如果我问,像,我的YouTube头像的名字是什么?我们只得到一个答案,你的YouTube头像的名字是K,如果你了解我,这就是100%正确的。
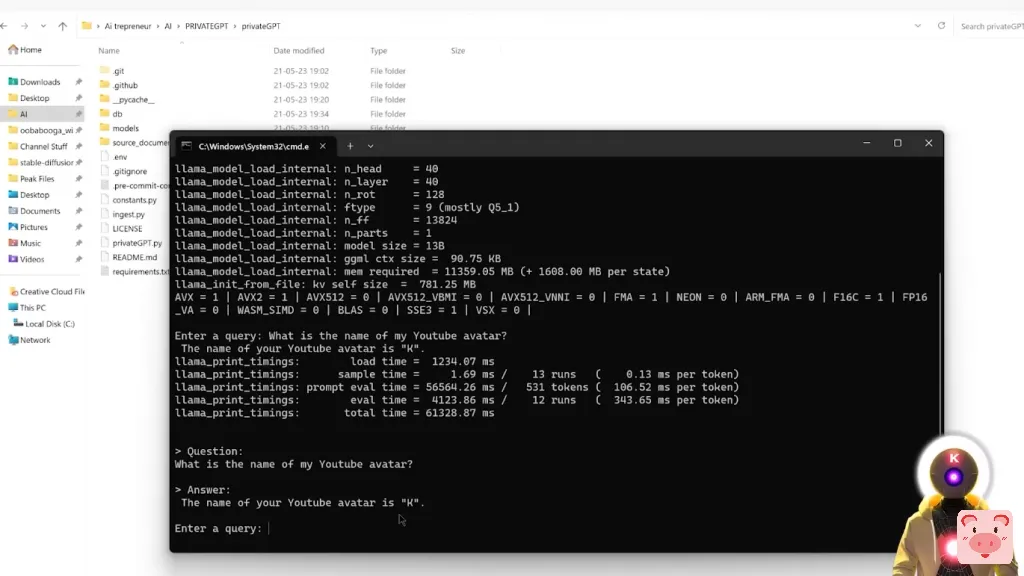
正如你在这里看到的,在答案之后,我们没有得到所有那些恼人的源文本。我们只有非常简单的问题、答案并且没有其他东西,这绝对是更干净的方式。所以,是的,你去那里。这是privateGPT,一个超级不可思议的神奇工具,你可以用它在非常复杂的文件中轻松找到信息。
而且你可以使用本地的LLM模型免费离线完成所有这些工作。虽然现在速度很慢,而且没有用户界面,但我认为很快我们就会有一个GPU版本,有一个非常漂亮的用户界面,这将使其更加可用,这就是为什么每一个开源软件都是一样的。这只是一个开始,随着时间的推移,一切都会变得更好。但就目前而言,它已经相当可用了,而且使用起来已经非常酷了。 所以,如果你可以的话,一定要试试这个,因为这非常好。这就是今天的内容,朋友们。非常感谢你们的观看。别忘了订阅并点赞,以支持YouTube算法。同时也非常感谢我的Patreon支持者们对我的视频的支持。你们真是太棒了!正是你们的支持,我才能为你们制作这些视频。非常感谢大家,我们下次再见。再见!