ChatGPT知识问答 |OpenAI Embeddings最佳本地化替代方案 | Instructor Embedding
作者:FancyPig | 发布时间: | 更新时间:
相关阅读
视频讲解
本期视频我们将继续延续上一期的使用ChatGPT实现知识问答,我们输入任意的网页链接,将网页链接解析成多个文档,存储Embeddings到知识库中,最后通过问答查询Embeddings最终转换成自然语言。依旧是同样的流程,但是本期视频,我们为大家进一步对比本地化Embeddings的实现方案,我们将使用Instructor Embeddings来平替OpenAI Embeddings,一方面节省API调用费用,一方面帮助大家实现部分私有化部署。这里顺便预告下一期,我们会提供一个完全本地私有化部署方案,敬请期待。
相关代码
图文讲解
如果你正在寻找OpenAI的大型语言模型和embeddings的开源替代品,这个视频是为你准备的。

在这个视频中,我们将把本地embeddings与OpenAI的embeddings进行比较,这些embeddings产生的响应质量会让你吃惊。我将向你展示的embeddings是最好的、最先进的开源embeddings。要创建一个用于信息检索的聊天,你需要两样东西。第一个是做语义搜索的embeddings,另一个是一个大的语言模型,用于根据使用embeddings检索到的文件生成自然语言响应。
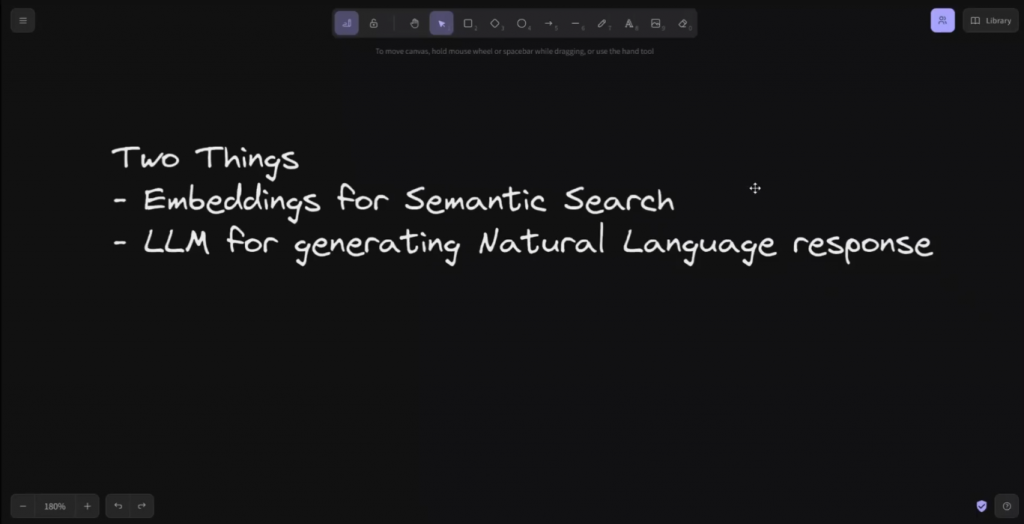
在这个视频中,我们要看的是第一部分的开源解决方案,但在随后的视频中,我们甚至要用个强大的开源模型来替换大语言模型。这里是架构图。因此,我将快速浏览一下这个问题。如果你是新来的,我有一个关于这个主题的详细视频,所以我将把一个链接放到那个视频。
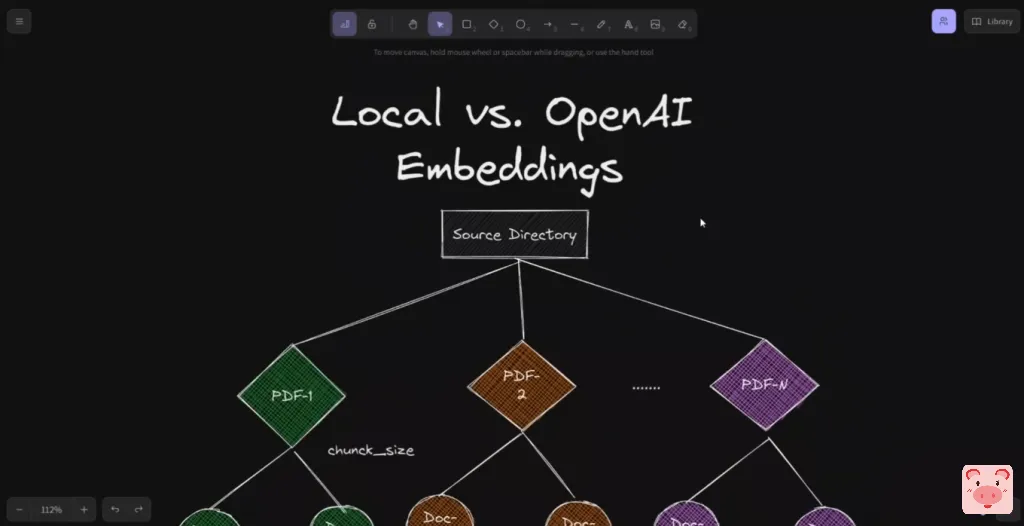
所以在这种情况下,我们将有一个文件夹,其中将包含多个PDF文件。然后我们将把这些PDF文件分成小的文件,因为我们将要使用的大型语言模型,它有一个有限的令牌限制大小,所以我们不希望超过这个限制。

接下来,我们将计算所有这些文件的embeddings。所以在我之前的视频中,我们使用OpenAI的API来计算embeddings。
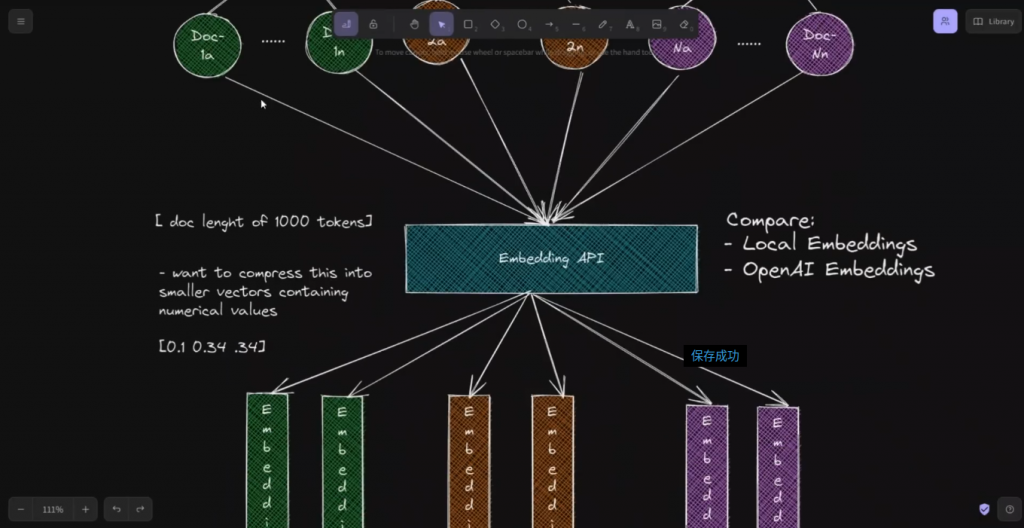
在这种情况下,我们将使用一个开源的解决方案,以及OpenAI的解决方案。我们要看的这个开源解决方案叫做Instruct Embeddings。

它是基于这项工作,当embeddings,任何任务,指令,微调,文本embeddings。所以这些都是经过微调的,已经存在的embeddings,可以生成文本embeddings为任何任务量身定做。这是一个非常简单的使用机制。我可能会再制作一个专门针对这些embeddings的视频,但只要记住它是最先进的embeddings之一,而且他们显示它在70多个不同的任务上取得了最先进的结果。所以,一旦我们计算出了embeddings,那么我们就把这些embeddings放在一个语义搜索矢量存储器中,这样就成为一个知识库。
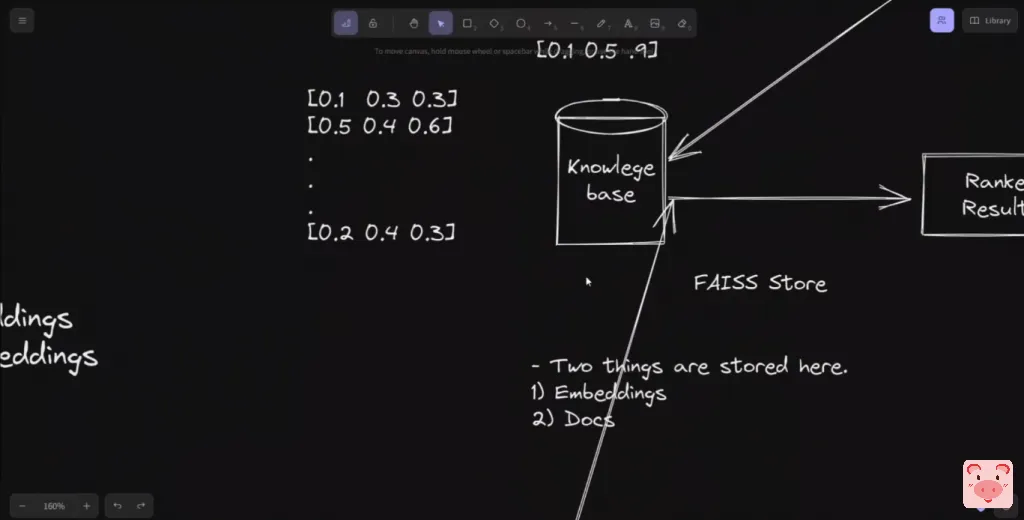
在这种情况下,我们使用FAISS作为一个矢量存储,但你可以看看其他一些选项。例如,有Pinecone,ChromaDB是另一个不错的选择。

现在就信息检索而言,所以当用户提出一个问题时,那么我们将使用相同的embeddings计算管道来计算embeddings。所以我们会得到我们问题的embeddings,然后我们会做一个语义搜索。所以它的工作方式是,你拿着embeddings,你把它和文档的embeddings进行比较,根据embeddings空间找到最相似的文档。

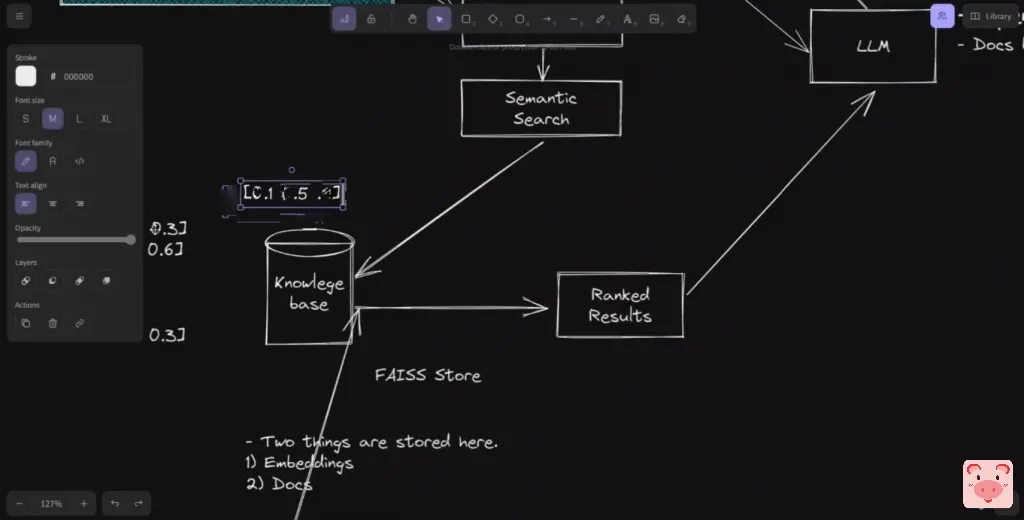
你得到结果,所以基本上你返回原始文件。然后我们把这些文件和问题一起输入,以得到一个回应。因此,我们检索到的文件,它们成为大型语言模型的上下文,并且基于使用该上下文的提示,大型语言模型将生成一个响应。在这种情况下,我们将使用OpenAI的DaVinci模型来生成响应,但正如我在随后的视频中所说,我们将研究一个开源的解决方案,你想替换这部分,对吗?而这就是用户获得响应的方式。所以这是对整体架构的一个非常快速的概述。我有几个更详细的视频,关于这个架构的所有方面,所以我建议你们如果是新来的,可以看一下这些视频。
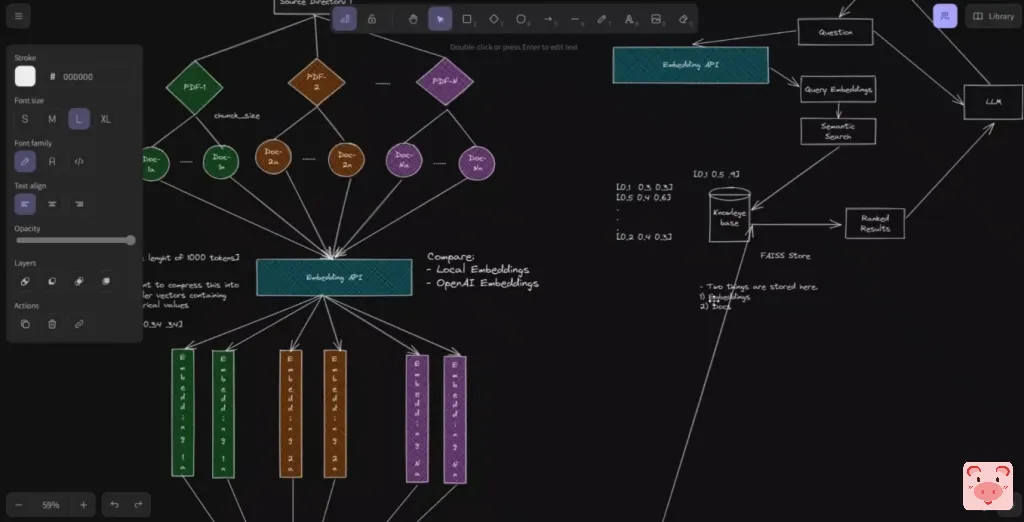
现在在这个视频中,正如我所说的,我们将对开源embeddings检索这些文件的能力做一个比较。我们判断检索质量的方法是,我们将直接比较与OpenAI的embeddings的响应,对吗?大的语言模型是完全一样的,所以如果它们都返回相同的文件作为信息,我们会期望Davinci模型产生的响应非常相似。所以这将是一个有趣的视频,请继续观看。好的,让我们看一下代码,看看这里发生了什么。所以首先我们要下载并安装所有需要的软件包。接下来你需要有你的OpenAI的API密钥,所以你可以从你的OpenAI的账户获得API密钥,对吗?

接下来我们要导入所有我们需要的不同软件包。所以我认为我们不需要ChromaDB,我在这里没有使用它,所以我要删除这个,甚至对于安装,我认为我没有安装它。

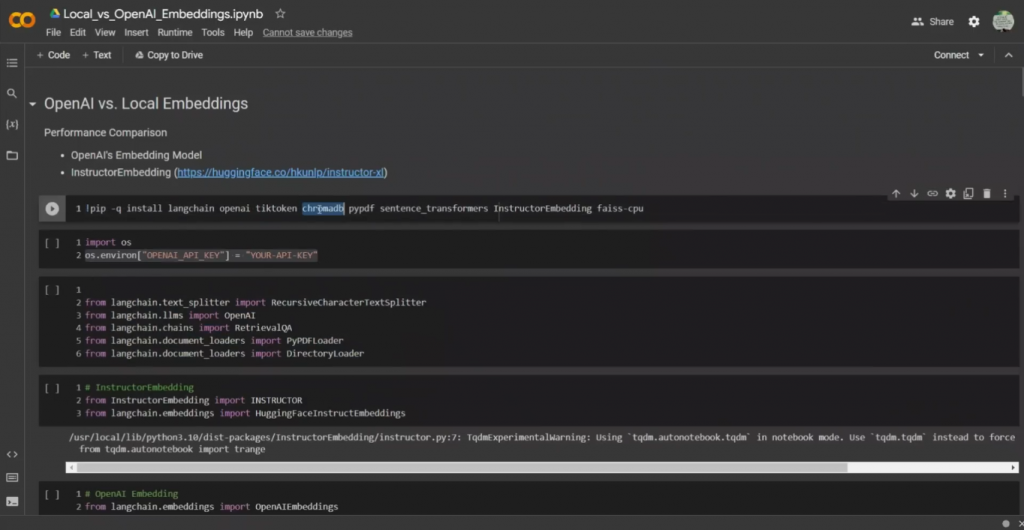
相反,我正在使用FAISS矢量存储。接下来我们要导入与我们的指令embeddings相关的包,所以这个包被称为instructor

还有HuggingFaceInstructorEmbeddings,这里正在加载。因为我们要在OpenAI的embeddings以及这些instructor embeddings之间做一个比较,所以我们也在导入OpenAI的embeddings。

现在,这种情况下的目标非常简单。embeddings将被用于文档检索,以找出哪些文档是最接近的。所以我们基本上是在谈论这个步骤,对吗?所以基于embeddings,我们试图找出最接近的文件或最相似的文件。然后我们将使用一个大的语言模型来创建一个基于这些文件的响应它们将被视为上下文,对吗?所以在这两种情况下,我们都将使用OpenAI的DaVinci模型来生成自然语言的回应。而我们的目标是看看使用开源embeddings是否能给我们带来类似质量的回应,因为如果信息来源完全相同,或者说两种情况下的上下文完全相同,那么DaVinci模型应该能产生非常类似的回应。接下来,我们只是与谷歌驱动器进行交互,所以我们将在这种情况下安装一个谷歌驱动器。
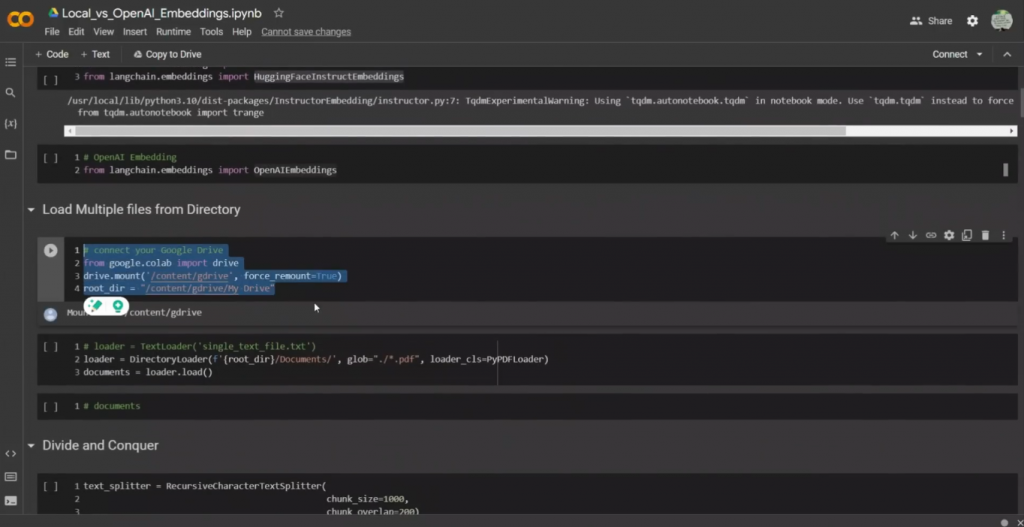
然后我们使用目录加载器来检索文件夹中的文件。在我的Google Drive中,有一个文件夹叫做文档,它可以包含不同的文件类型。它可以有文本文件、PDF文件,任何你想要的东西,对吗?但我特别想找的只有PDF文件。如果你想检索文本文件,你将简单地用文本文件扩展名替换这个PDF,对吗?
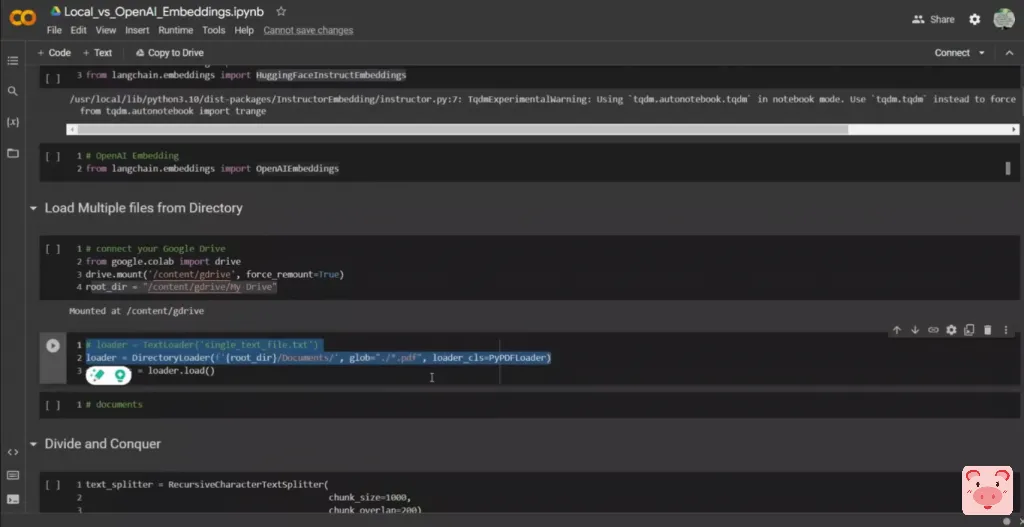
所以这将成为txt。这将创建一个加载器,从我的目录中加载所有的PDF文件,然后它们将被放在这个文档对象中。现在让我快速告诉你我们正在处理的是什么类型的文件。
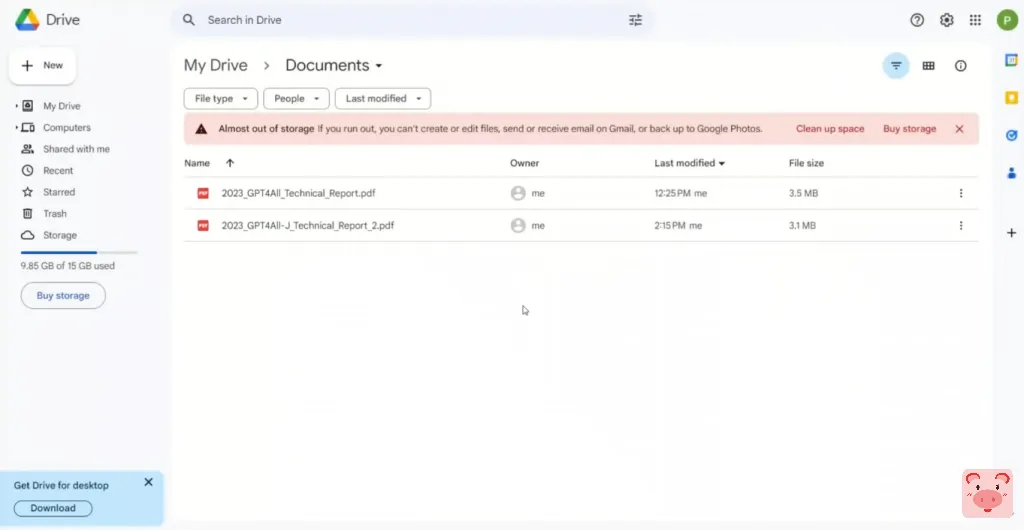
而这将是一个非常棘手的任务,需要完成。所以在这种情况下,我所做的是我去下载与GPT4ALL有关的技术报告所以这就是他们发布的第一版技术报告。

然后我实际上下载了GPT4ALL-J模型技术报告。

这个模型是,这是一个可以在商业上使用的模型,所以你可以使用它进行商业应用。现在棘手的是,在这两种情况下,作者都是一样的。技术报告的内容也基本相同。没有太大的区别,因为它讲的是和第一个技术报告完全一样的东西。所以我想看看,如果你有非常相似的文件,而且它们包含非常相似的信息,所以这是要从哪里检索信息。好的。接下来,我们把这些文件加载,对吗?

所以在这种情况下,我们将只有两个PDF文件,并把它们分成更小的文件或更小的块。所以我们选择的大块大小是1000个左右的字符,标记,然后有会有200个标记的重叠。现在我们为什么要这样做?所以我们要使用的大语言模型,他们有一个有限的上下文窗口,为他们可以互动的令牌限制,对吗?所以你希望它比这更低。我在之前的视频中已经更详细地解释了这个问题,所以我打算放一个链接到那。如果你有兴趣,可以去看看,对吗?所以基本上,我们把它分成1000个令牌块,对吗?这里是一个例子,说明它可能看起来像什么。经过这样的划分过程,我们最终得到的不是两个文件,而是22个文件。

如果你是一个视觉学习者,那么这就是最终要发生的事情。你有一个PDF,现在你要在这个PDF的基础上创建多个文档。好的,下一步是为我们的每个文件获得embeddings,对吗?所以,正如我所说,我们将使用两个embeddings。

一个是要做instructor embeddings,这是开源的,另一个是来自OpenAI。好吗?现在,我写了两个不同的辅助函数,你可以在自己的代码中使用。所以我想做的是存储我的embeddings,来自文档的embeddings,对吗?所以,一旦你通过embeddings运行这些,无论结果如何,我都会把这个向量存储起来,然后用另一个小的辅助函数来检索这些,因为我们不希望反复计算它们。所以首先看一下,让我们看看如何下载或获得instructor embeddings,对吗?所以我们要用LangChain来做这个。我们要使用的函数叫做HuggingFaceInstructEmbeddings,对吗?所以这与普通的HuggingFaceEmbeddings不同。
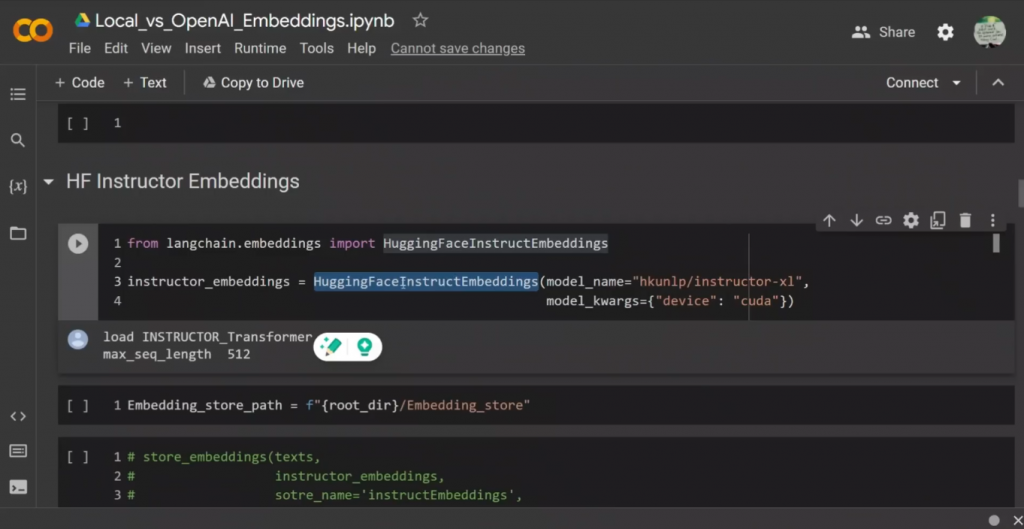
当涉及到开源embeddings时,这似乎是最先进的,对吗?所以你需要传入两个对象,或者两个变量。所以第一个是embeddings的类型。所以Instructor-xl,这就是我们要使用的embeddings。第二个是你是否想在GPU或CPU上运行它。所以在这种情况下,我通过CUDA。所以它是在GPU上运行的。但如果你愿意,你实际上可以在CPU上运行,尽管会慢很多,对吗?当我们运行代码时,它将下载,我想,大约5千兆字节的文件。

但它只会做一次,然后就会储存在你的本地机器上。正如你在这里看到的,我在谷歌驱动器上运行这个。但你可以在本地运行代码,然后你会有相应的instructor embeddings存储在本地。它所能接受的最大序列长度大约是512。所以这里有我刚才提到的两个函数调用。你实际上可以取消注释并运行它。
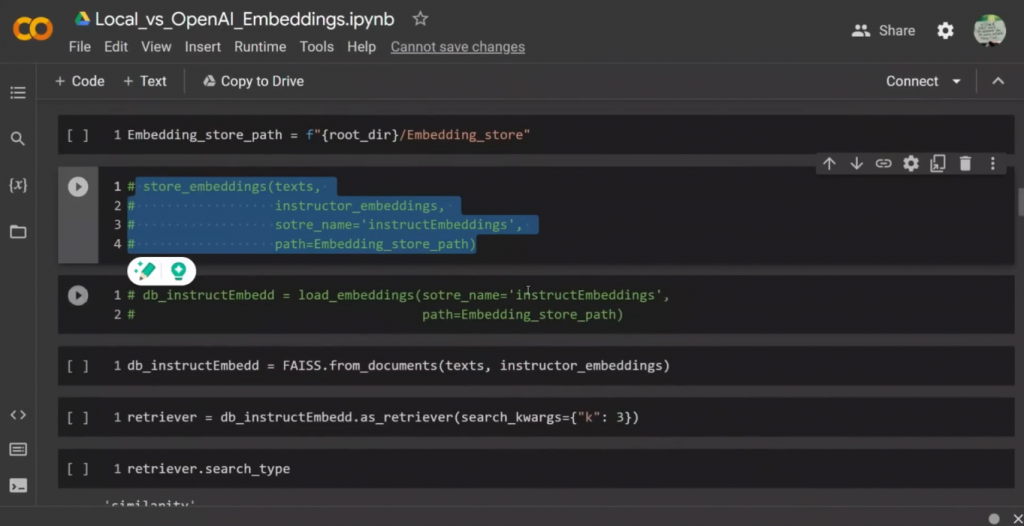
所以它既要执行代码,又要在本地存储embeddings,然后再检索它们。但在这里,我只是想向你展示一个逐步的过程。所以我们是用FAISS作为一个矢量存储,对吗?而在这种情况下,你把我们创建的文件,相应的embeddings对象传递给instructor embeddings,对吗?
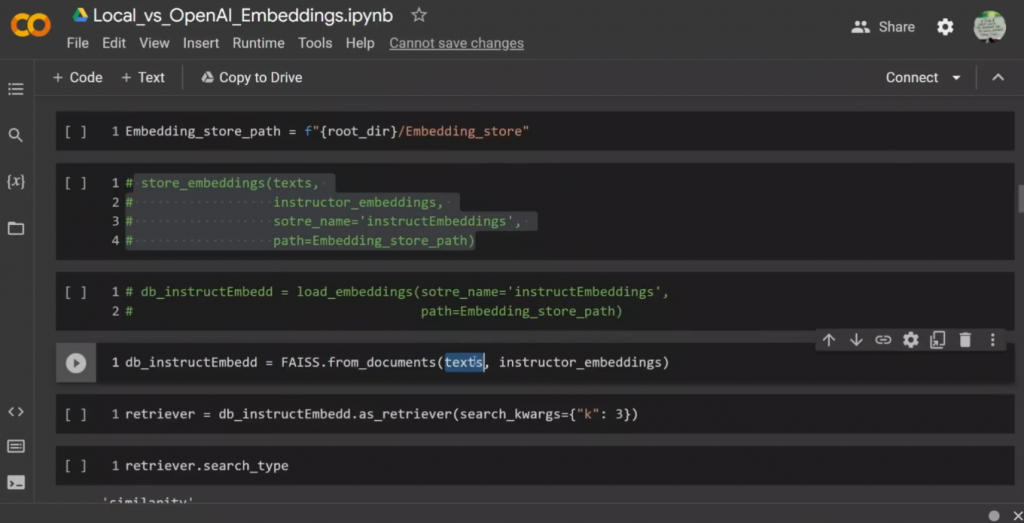
而你会得到相应的向量存储。现在,你可以把这个向量存储作为一个信息检索对象。
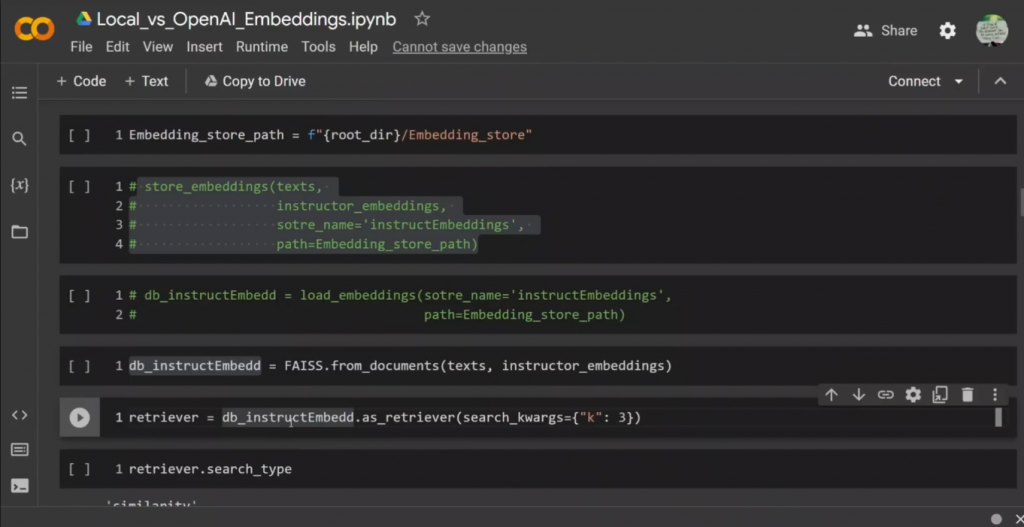
检索器是Langchain中的一种特殊类型的对象,你可以用它来进行信息检索,对吗?所以我们把矢量存储,作为一个检索器,然后我们说,好的,给我三个类似的文件,对吗?

检索器的类型是相似性。

所以我们要看最相似的,在这个情况下,文件的数量是三个。
现在,就架构图而言,所以这就是我们所处的阶段,对吗?

所以你有你的原始矢量存储。你得到你的查询的embeddings,对吗?而检索器将简单地从你的知识库中挑选三个最相似的文件。好的,我想强调的一点是,如果你正在寻找简单的信息检索,而你想找出信息的来源,实际上你可以停在这步,因为,比方说,如果你运行这个,你会得到相关的文件,对吗?所以在这种情况下,我的疑问是,谁是GPT4ALL报告的作者,对吗?

如果我说得到相关文件,并在检索器对象上运行这个,我会得到一个三个不同文件的列表,这里是最相似的第一个文件,对吗?所以它将有从你的源文件中提取的文本,好吗?现在,第二步将是,你将使用这个作为你的大型语言模型的背景,以更自然的语言创建一个大小的答案。但是,如果你只是简单地寻找来源,你实际上可以在这里停止它。而如果你想真正地继续下去,得到自然的回应,那么我们就必须建立个链。我们将要使用的链是一个检索问题答案链,对吗?有多个参数需要传递。所以第一个是大的语言模型,它将把回答转换成自然语言。在这种情况下,我们使用的是OpenAI的DaVinci模型,但你可以使用任何你想要的模型。在下一个视频中,我将向你展示如何实际使用一个开源模型,甚至作为一个大型语言模型,对吗?所以请留意这一点。第二个参数是我们刚刚为我们的instructor embeddings创建的检索,对吗?我们希望这个链能返回源文件,所以它实际上会返回一个像这样的文件源,对吗?而链的类型是stuff。现在我们为开放源码的embeddings做了embeddings部分,instructor embeddings。现在我们需要为OpenAI的embeddings做同样的事情。我这样做是因为我想做一个比较,但实际上你可以直接使用它,对吗?所以首先,我只是简单地用OpenAI的embeddings创建一个叫做embeddings的对象,对吗?然后把这个embeddings和文本文件一起传递,创建一个矢量存储,好吗?

然后我们做同样的过程。我们根据我们使用OpenAI的embeddings创建的向量存储创建一个相应的检索对象。然后再一次,我们将为此创建另一条链。所以这个链被称为问题答案链,这就是OpenAI的版本。接下来我们简单地写几个辅助函数,目的是简单地将回应改为格式化的回应。这是我实际复制的东西。我将在视频的描述中写上这个来源。
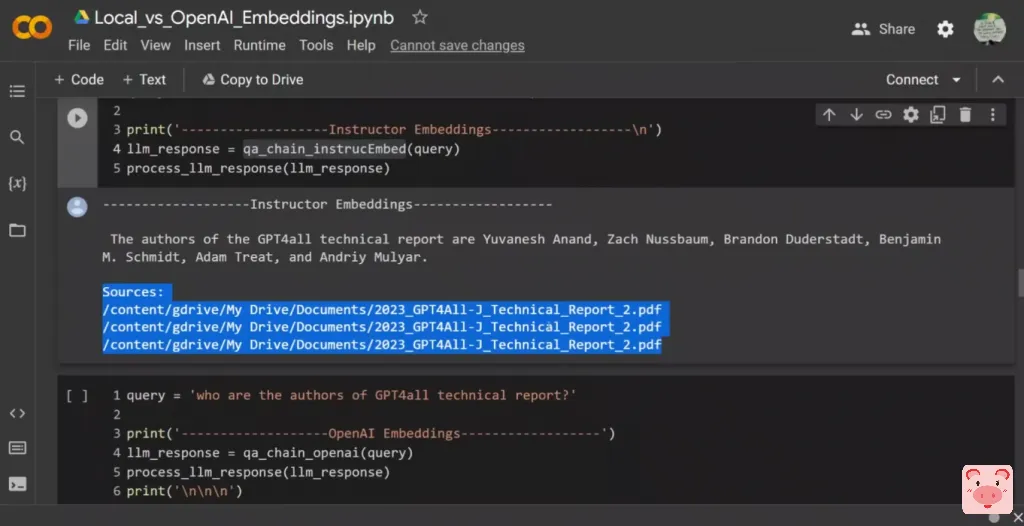
所以我们需要测试它们,对吗?所以这里是我的第一个疑问。谁是GPT4ALL报告的作者?

现在,正如我所说的,这是非常棘手的问题。这两份技术报告所包含的信息几乎是相同的,对吗?所以我主要是在寻找它所返回的信息,不管这是否正确。所以我主要是在寻找来源。所以,如果我们使用instructor embeddings,回应,GPT4ALL报告的作者是,然后你有这个名字,它是正确的,好吗?还有它所引用的来源,所以它所选的三个来源都是来自第二个技术报告,对吗?
但具体来说,我问的是GPT4ALL模型,而不是GPT4ALL-J,对吗?
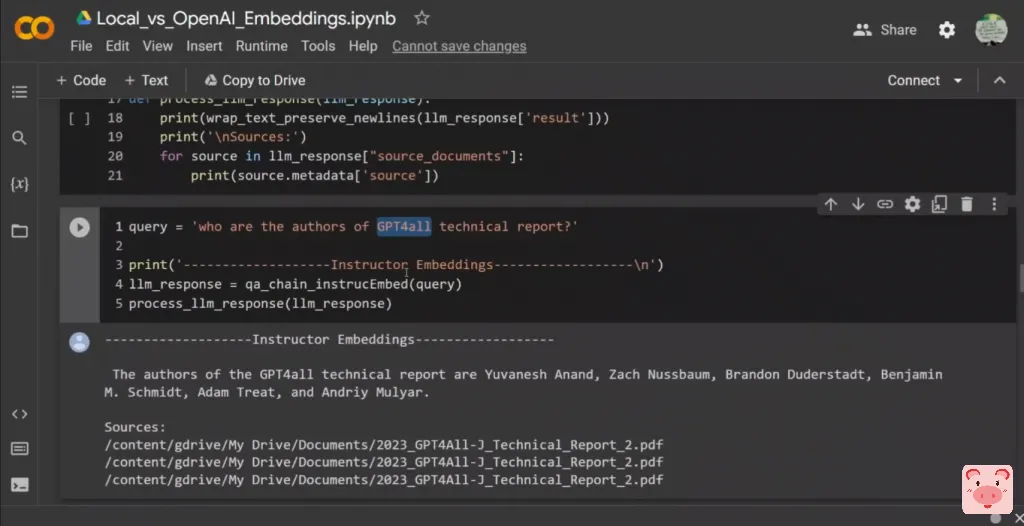
但我仍然认为在这两种情况下,作者是一样的,所以我们可以说是正确的。现在如果我们使用OpenAI的embeddings,DaVinci模型所创建的响应只是返回作者的名字,而不是任何其他细节。
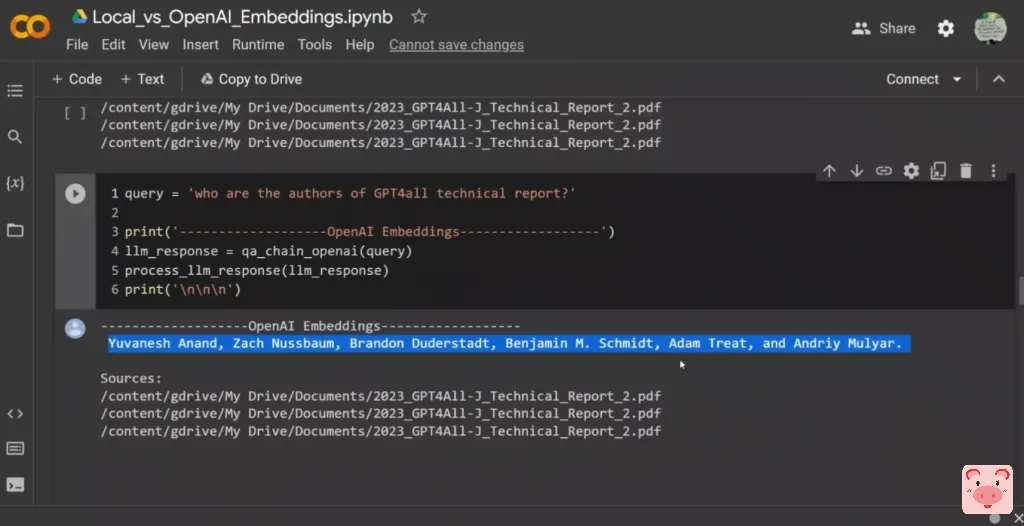
所以我认为它还是不错的,因为这个响应是正确的。然后它所引用的来源实际上也是第二份报告。因此,也许在下一个视频中,我将看一下它所返回的完全相同的文件。第二个查询,所有GPT4ALL-J模型是如何训练的?所以我们谈论的是第二个报告中包含的这些信息,对吗?在这种情况下,我认为他们两个人的反应都很好,然而他们给出的反应非常不同。所以看起来,这两个embeddings发现的文件是相似的,但却非常不同。因此,例如在第一个中,它说模型是在一个大规模的助手互动的策划语料库中训练的,包括单词问题、多转对话、代码、诗、歌曲和故事,对吗?所以它看的是它所使用的数据集的类型,对吗?在第二种情况下,它说它是用LoRa训练的,这就是用来训练它的算法,然后它给我们进一步的信息,关于使用的例子的数量和epochs的数量是什么。
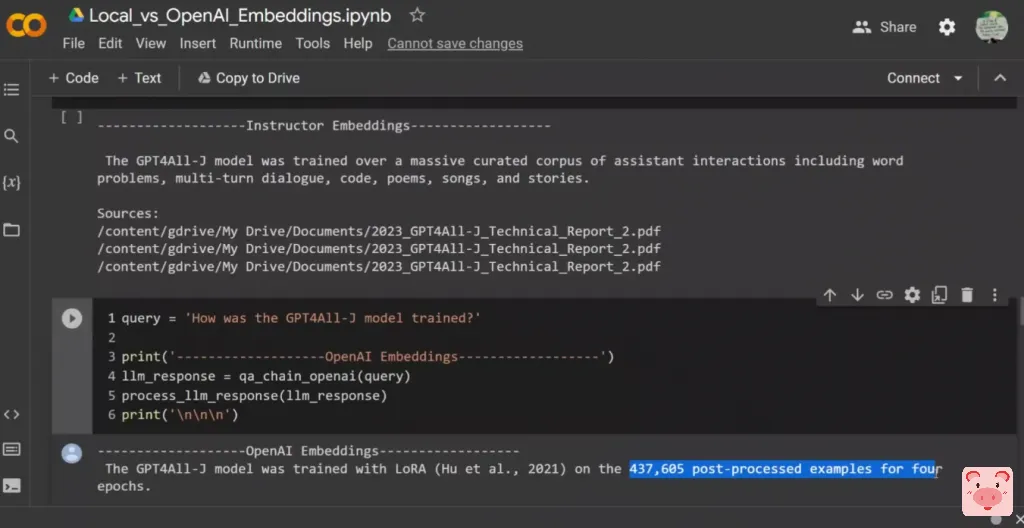
正如我之前所说,它似乎挑选了不同的文件,这就是为什么它产生了两种不同的反应。他们在某种意义上都是正确的,但我认为OpenAI的embeddings在这个特定的情况下做得更好。这实际上是一个有趣的问题。所以我问它,GPT4ALL模型训练费用是多少?而且我在期待它能从第一份技术报告中获得信息。所以就来源而言,这里的Instructor embeddings实际上从第一份技术报告中找到了一份文件或一个片段,作为前三名的一部分,对吗?但回答是GPT4ALL模型训练的成本在OpenAI的信用中约为800美元,他们使用的Lambda实验室的GPU为100美元。

现在相比之下,OpenAI的embeddings的答案只是200美元。

我实际上回去看了一下。所以看起来,第一个,也就是开源embeddings,它从这里挑选了信息。

所以在GPT4all和GPT-J模型之间,到目前为止,我们已经花了大约800美元的OpenAI信用来生成所有的训练样本,我们公开发布给社区,对吗?

所以如果你看一下数据整理部分,这个信息似乎是正确的。现在,我们从OpenAI的embeddings得到的第二个回应,它来自这里。

所以信息,相关信息是我们发布的模型可以在GPU单元的纸质空间上训练大约八个小时,总成本为800美元。所以这不是实际训练模型的成本,而是如果你想再次重新训练它。但我不确定这100美元是怎么来的。

好的,还有几个问题。那么,GPT4ALL-J使用的是什么许可证?所以这是第二个模型或更新的版本,对吗?而且它说的是Apache 2,这是正确的,它引用了第二份技术报告,第一份,然后是第二份作为来源,对吗?可能是混淆了GPT4ALL与GPT4ALL-J,对吗?GPT4ALL-J,对吗?连我都觉得很困惑,对吗?而在这种情况下,OpenAI embeddings的答案是一样的,尽管信息来源或源文件都在第二份技术报告中。好的,我问的下一个问题是,用于训练GPT4ALL的训练数据集的大小是多少?
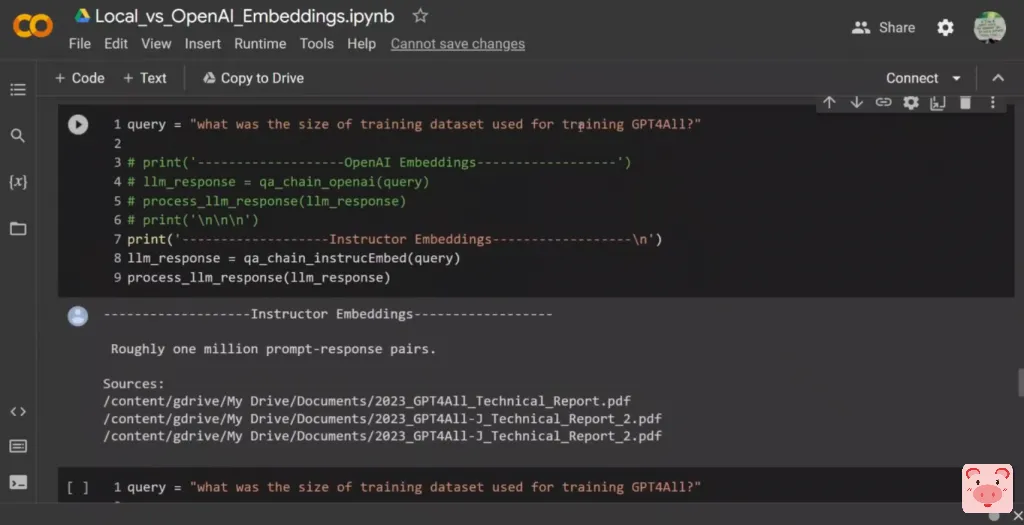
所以这又是一个棘手的问题。在第一种情况下,它得出了大约100万个提示-回答对。
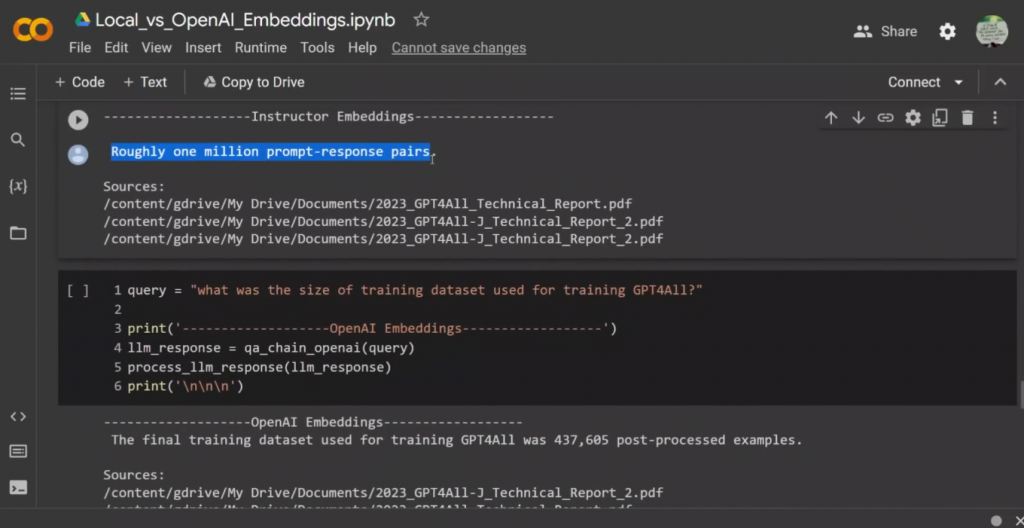
这是第一个技术报告中的内容,但我认为它说的是原始的LLAMA模型,而不是对GPT4ALL进行训练。第二个答案似乎是正确的。现在,我就GPT4ALL-J模型问了同样的问题,两个模型实际上都得出了,或者说两个embeddings都得出了正确的答案。现在我问,这是在两个技术报告中都没有的东西。所以我说,哪个MPT-7B模型是最好的?
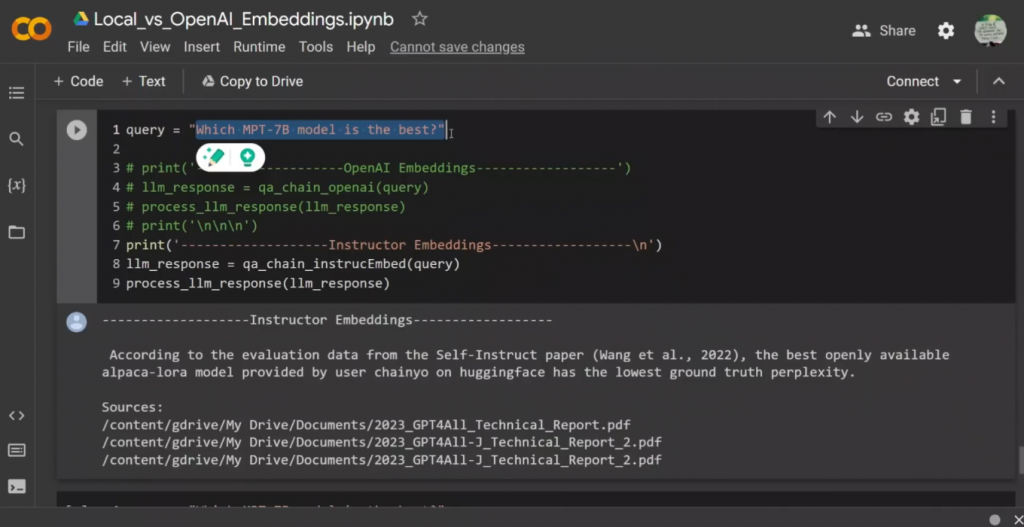
这与Mosaic ML模型有关吧?
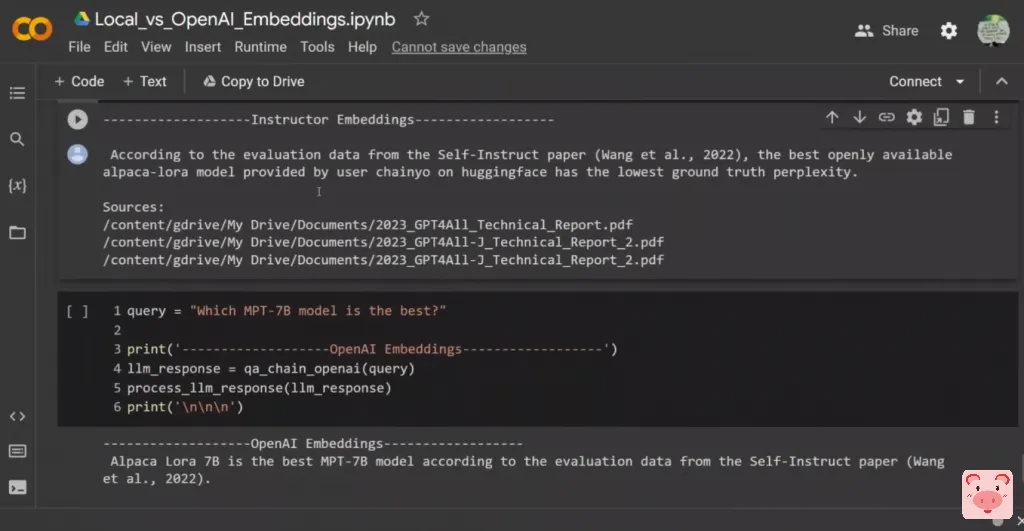
而在这两份技术报告中没有任何信息,但它说,根据自学论文的评估数据,最好的公开的Alpaca-LoRa模型,这实际上是一个70亿的参数模型,它选了这个作为答案,对吗?而第二种情况,同样,它挑选了Alpaca LoRa 7B是根据数据集的最佳MPT模型。所以这肯定是错的,对吧,因为它编的是,好吧,有一些与MPT-7B模型相关的信息,这是不存在的。
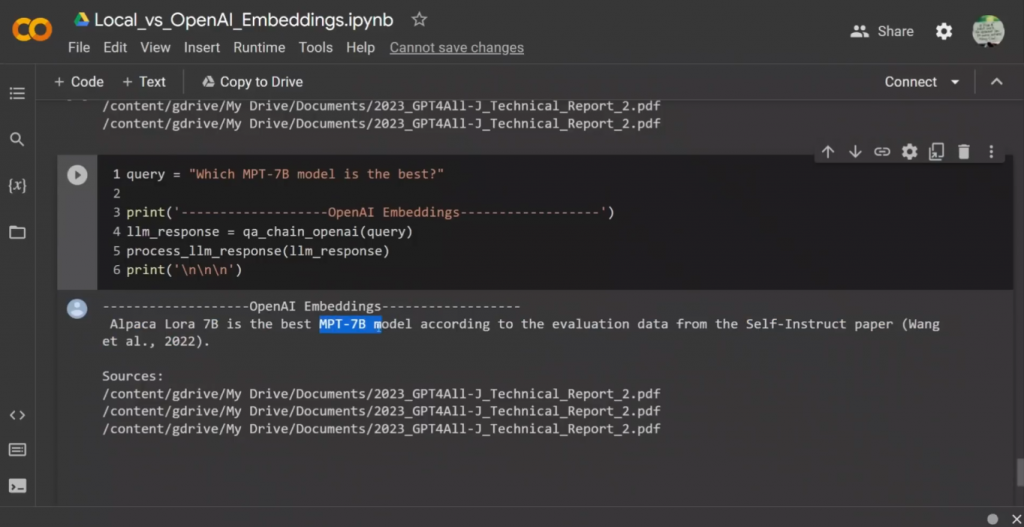
所以你实际上可以通过提示工程来解决这个问题。有一些方法可以限制大型语言模型的幻觉,我们将在新的系列视频中谈论这些。所以这是一个很大的。我最后的想法。所以看起来即使使用开源embeddings,特别是instructor embeddings,他们实际上产生非常相似的质量反应。肯定有一些情况下,反应会有一些偏差,但我认为总体来说,这些都和OpenAI的embeddings一样好。而这也是为什么我实际上在考虑完全远离OpenAI的embeddings,因为有几个原因。首先,如果这些东西和OpenAI的一样好,你其实不需要付钱。成本是零。第二,如果你担心发送你的信息,那么至少你在限制你所发送的信息量。但是,如果你能用一些开源模型代替大的语言模型,而不是使用OpenAI的DaVinci模型,那么我们甚至可以照顾到所有的隐私问题。而在下一个视频中,我将向你展示如何能用一个开源模型作为替代OpenAI的DaVinci模型。我希望这个视频是有用的。我们在这个视频中涵盖了很多内容。如果你有任何问题,请把它们放在下面的评论区。我将尽力回答他们。如果你有任何业务问题,或者你想为你的自己的企业、网站或其他领域实施一个类似的系统,而你需要技术专长,你可以实际联系我。我已经开始为人们提供咨询,解决他们的技术问题,所以我很乐意帮忙。如果你是新来的,还没有订阅,可以考虑订阅这个频道。请按下那个铃声通知按钮,这样你就不会错过新的精彩视频。谢谢你的观看。在下一个节目中见。