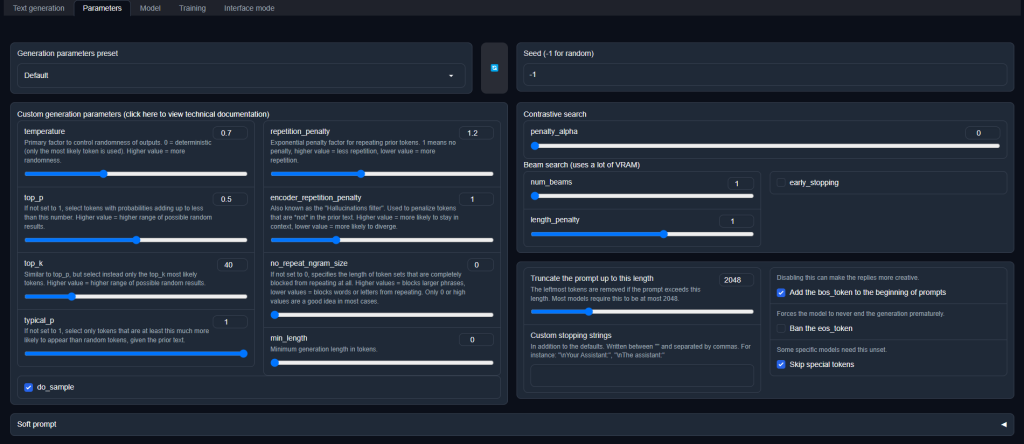
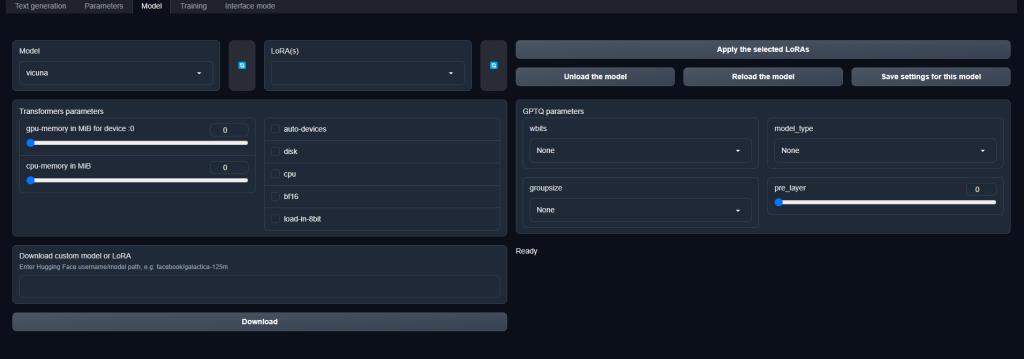
如何本地量化部署大规模语言模型 | 仅需1/4内存 | llama.cpp + text-generation-webui
作者:FancyPig | 发布时间: | 更新时间:
杂谈
其实在之前,我们分享的视频里,作者已经非常详细的讲解了整个过程,但是很多热心网友表示还是希望出一个图文教程,因此,今天给大家带来一个详细的图文教程!
相关阅读
思路
- 使用ggerganov/llama.cpp生成量化后的模型(当然,你也可以用命令行运行)
- 使用oobabooga/text-generation-webui的Web界面(支持Websocket、Restful API)
为什么要量化
这个问题,我们看一个表格,对比下就知道量化的意义了,量化后可以使用更小的内存就能跑模型
| 模型 | 原始大小 | 量化大小(4 位) |
|---|---|---|
| 7B | 13 GB | 3.9 GB |
| 13B | 24 GB | 7.8 GB |
| 30B | 60 GB | 19.5 GB |
| 65B | 120 GB | 38.5 GB |
详细讲解:在自然语言处理中,模型的大小对计算资源和存储资源的要求非常高,而量化是一种压缩模型大小的技术。在量化过程中,模型参数的精度被减少,从而降低了模型所需的存储空间。量化通常会导致一定程度的精度损失,因为降低精度会导致模型无法完全准确地表示某些特征或模式。但是,通过调整模型的训练和量化过程中的参数,可以尽量减小精度损失,同时使模型大小更小,更易于存储和运行。
服务器环境
我们这里使用的是阿里云GPU服务器
- 24核93GB
- GPU显存16GB
你不一定要这样的配置,你的配置取决于你要运行什么样的模型的,我们在上面给的表格其实就比较清晰的告诉你了,比方说你要部署7B的模型,那3.9GB的CPU内存就够了……
部署教程
llama.cpp量化模型
如果你对量化的详细过程不感兴趣,我们可以直接选取现成的使用
我们分享了一个Hugging Face上热心网友已经量化好的模型
| 模型名称 | 特点 |
|---|---|
| ggml-vicuna-13b-1.1-q4_0 | 快速,但准确性较差 |
| ggml-vicuna-13b-1.1-q4_1 | 更准确,但速度较慢 |
| ggml-vicuna-13b-1.1-q4_2 | 基本上是更好的q4_0,速度相近,但准确性更高 |
| ggml-vicuna-13b-1.1-q4_3 | 基本上是更好的q4_1,准确性更高,但速度仍然较慢 |
| ggml-vicuna-13b-1.0-uncensored | 在q4_2和q4_3中可用,是一个版本 |
首先,我们将项目下载到服务器上
git clone https://github.com/ggerganov/llama.cpp如果你对命令行不熟悉,也可以直接进入llama.cpp项目页面,点击Download ZIP

之后将llama.cpp-master.zip压缩包上传到服务器,解压之后进入llama.cpp-master目录
开始编译
make
实际上,你也可以直接在llama.cpp中使用终端运行模型,但是我们为了有更好的扩展性(拥有WebUI、API等诸多功能),所以才选择使用oobabooga/text-generation-webui来运行模型。
因此,我们现在要做的就是转换+量化完模型,就从llama.cpp中弃坑,转向text-generation-webui了。
通常情况下,如果是一个新的模型发布,譬如Vicuna-13b-delta-v1.1,你大概可以看到文件如下

我们需要将其上传到models文件夹中

上传之后大致效果如下,我的因为是13B参数的,因此我在models里建一个文件夹叫13B
这里是我们下载的Vicuna-13b-delta-v1.1
- config.json
- gitattributes.txt
- pytorch_model-00001-of-00003.bin
- pytorch_model-00002-of-00003.bin
- pytorch_model-00003-of-00003.bin
- generation_config.json
- pytorch_model.bin.index.json
- ggml-vocab.bin
- README.md
同时我们还要放入LLaMA权重
- checklist.chk
- consolidated.00.pth
- consolidated.01.pth
- params.json
这里需要注意的是models文件夹里还要上传2个文件
- tokenizer_checklist.chk
- tokenizer.model
单独上传的文件需要自行申请,申请入口
因为这个模型权重似乎是不允许商用的,因此互联网上基本上看不到这个权重文件的
但之前有一个Github项目里似乎有分享
https://github.com/facebookresearch/llama/pull/73/files

这里似乎有种子链接可供下载
magnet:?xt=urn:btih:ZXXDAUWYLRUXXBHUYEMS6Q5CE5WA3LVA&dn=LLaMA这里测试是可以下载的

我们只需要选择需要对应的模型即可,我们这里要使用的是13B的

然后安装Python的依赖
python3 -m pip install -r requirements.txt之后将其转化为Float-16格式的
python3 convert.py models/13B/转换为Float-16格式之后在进行量化
./quantize ./models/13B/ggml-model-f16.bin ./models/13B/ggml-model-q4_0.bin 2text-generation-webui
接下来,我们可以上传项目文件text-generation-webui-main.zip并解压

然后进入models中,我们这里因为是vicuna,因此我们创建一个目录,上传我们量化好的模型ggml-vicuna-13b-1.1-q4_1.bin
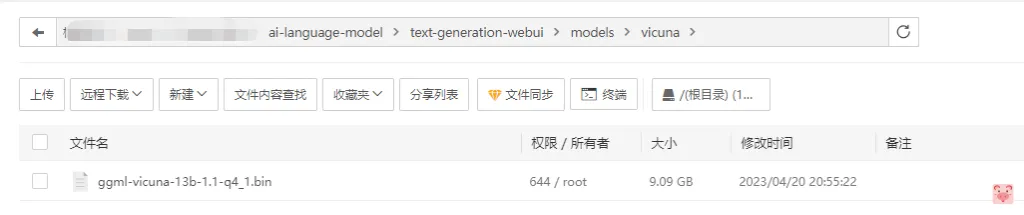
之后回到项目目录,安装依赖
pip3 install -r requirements.txt然后启动项目
python3 server.py --model vicuna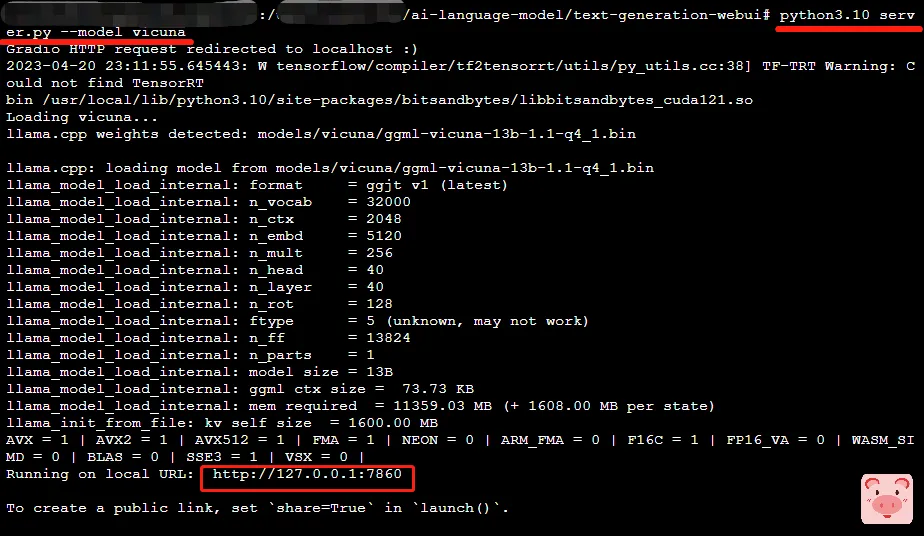
这里可以看到是已经启动成功了
之后你可以使用宝塔面板的反向代理,绑定一个域名就可以访问了
界面展示
这里功能还是非常强大的,无论是问答还是在线训练