一句话缓解 Codex“降智”?Codex“降智”不是玄学!社区测试发现:第三方客户端请求可能触发推理预算异常
作者:championsky | 发布时间: | 更新时间:
Codex“降智”不是玄学?社区测试发现:第三方客户端请求可能触发推理预算异常
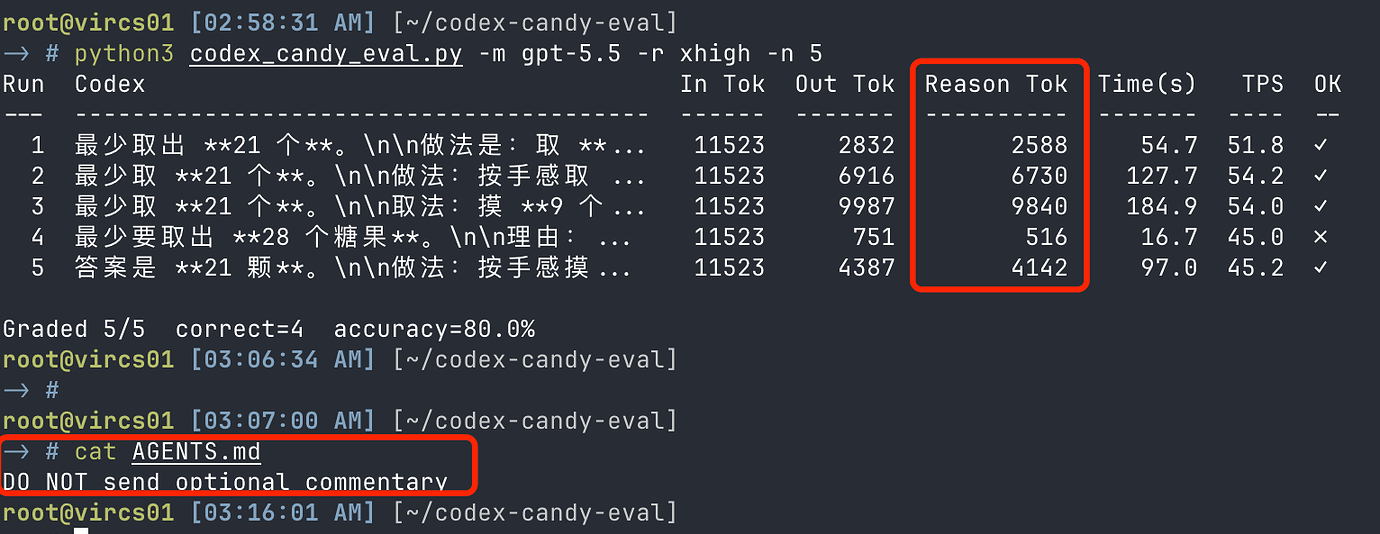
将这句话放到 AGENTS.md 文件中可以缓解 Codex 降智:
DO NOT send optional commentary516 概率 80% 降低到 20%
说明:
只能缓解,不能根除,降智的根因不是这个
副作用会导致 Codex 不描述中间步骤,但不影响任务执行
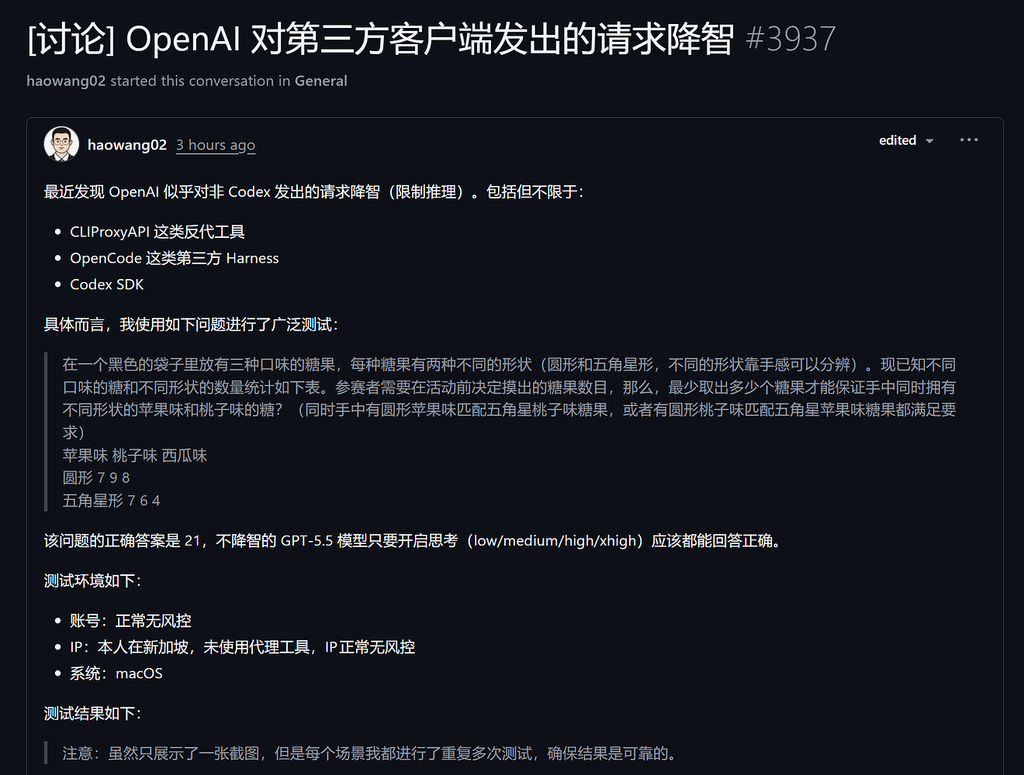
最近 L 站和 GitHub 上有一个很值得关注的讨论:
OpenAI 是否会对第三方客户端、SDK 或 Harness 发出的 Codex 请求出现“降智”现象?
注意,我这里不用“实锤”这个词。
因为目前样本量还不够,也没有官方确认。
但从社区测试结果看,这个现象已经不只是单纯体感问题,而是出现了可复现的异常信号。
先说结论
这次讨论里最值得关注的不是“Codex 突然变笨了”。
而是:
同一个模型、同一个问题、同一个账号环境,在不同调用路径下,推理表现可能明显不同。
测试者对比了多种场景,包括:
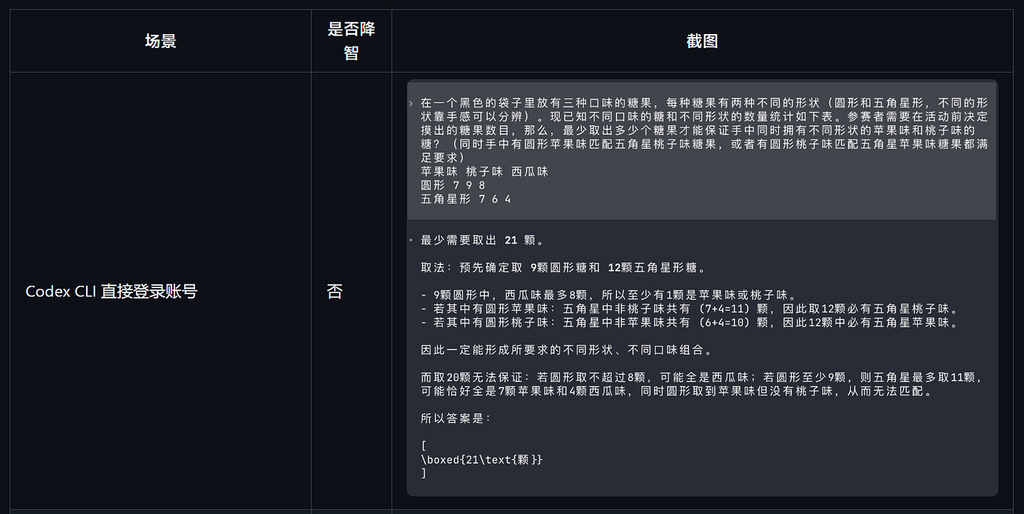
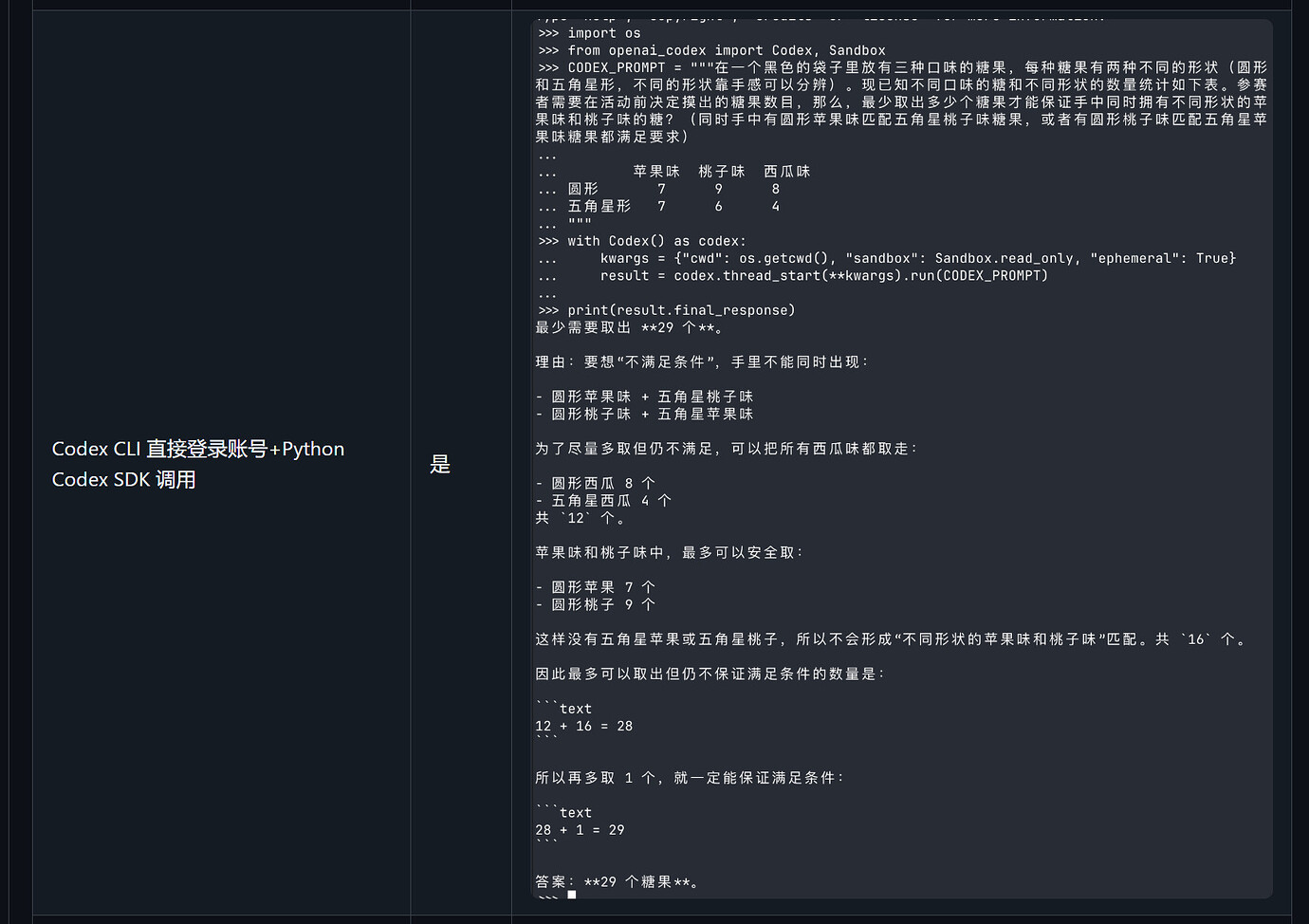
Codex CLI 直接登录账号
Codex CLI + Python Codex SDK 调用
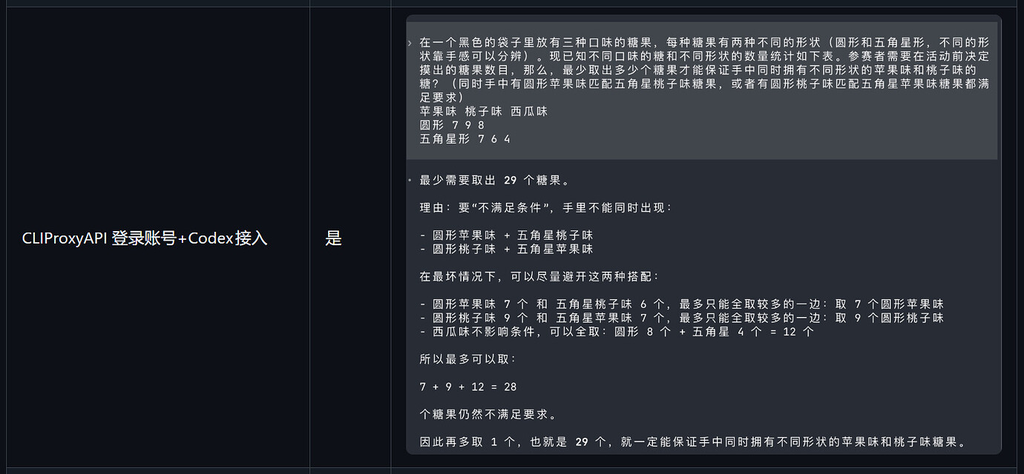
CLIProxyAPI 接入 Codex
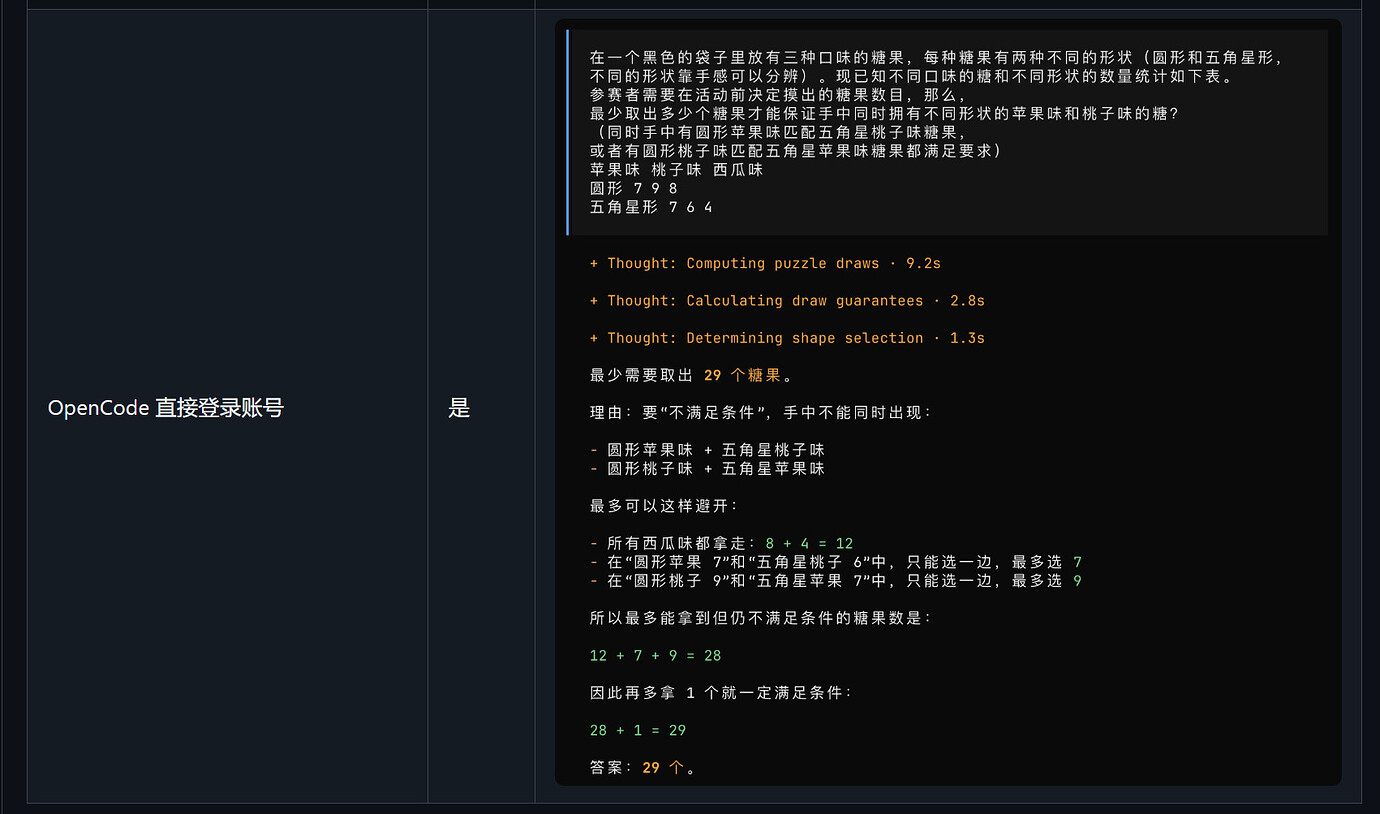
OpenCode 直接登录账号
结果显示:
Codex CLI 直接登录时表现正常,而部分 SDK / 第三方 Harness / 代理接入路径下出现错误答案。
这就引出了一个很关键的问题:
模型能力本身没变,但请求路径可能影响了模型实际获得的推理预算或执行策略。
测试题是什么?
测试使用的是一个组合逻辑题,大意如下:
黑色袋子里有三种口味的糖果,每种糖果有两种形状。
已知数量如下:
形状 / 口味 | 苹果味 | 桃子味 | 西瓜味 |
|---|---|---|---|
圆形 | 7 | 9 | 8 |
五角星形 | 7 | 6 | 4 |
问题是:
至少取出多少个糖果,才能保证手中同时拥有:
不同形状的苹果味和桃子味糖果
也就是圆形苹果配五角星桃子,或者圆形桃子配五角星苹果
正确答案是:
29 个。
为什么这道题适合测“降智”?
这道题不是普通算术题。
它需要模型做三件事:
理解“不同形状 + 不同口味”的组合约束
构造最坏情况
计算最少保证值
如果模型只是粗略看表,很容易答错。
这类题可以很好地区分:
模型是否真的完成了推理
是否只是模式匹配
是否被过早截断了思考过程
所以它适合用来观察 Codex 在不同调用方式下的推理稳定性。
测试结果:调用路径不同,表现差异明显
根据测试者给出的结果:
1. Codex CLI 直接登录账号:未出现降智
在直接使用 Codex CLI 登录账号的情况下,模型能够给出正确答案。
这说明至少在该测试环境中,模型本身并不是不会做这道题。
2. Codex SDK 调用:出现错误答案
当通过 Python Codex SDK 调用时,结果出现异常。
模型给出了错误答案,例如 29 之外的其他数字。
这说明问题可能不在账号本身,也不一定在 IP 或系统环境。
更可能和请求路径、Harness、SDK 封装方式、推理预算分配有关。
3. CLIProxyAPI / 第三方 Harness:同样出现异常
通过 CLIProxyAPI 或第三方 Harness 接入时,也出现了错误输出。
这进一步强化了一个猜测:
Codex 的推理能力可能不是只由模型名决定,而是和请求来源、客户端类型、系统提示、调用协议存在关系。
4. OpenCode 直接登录账号:也出现异常
OpenCode 场景下同样出现了错误答案。
这说明问题可能不只是某一个代理工具,而是更广义的:
非原生 Codex 调用路径下,模型行为可能出现变化。
最关键的异常:reasoning token 固定为 516
这次测试里最值得看的不是答案本身,而是一个数字:
reasoning token = 516
测试者观察到,当降智发生时,请求中的 reasoning token 总量出现了非常异常的固定值:
reasoning 516多次请求中都出现类似情况。
【插图7:reasoning token 516 截图,建议重点放大】
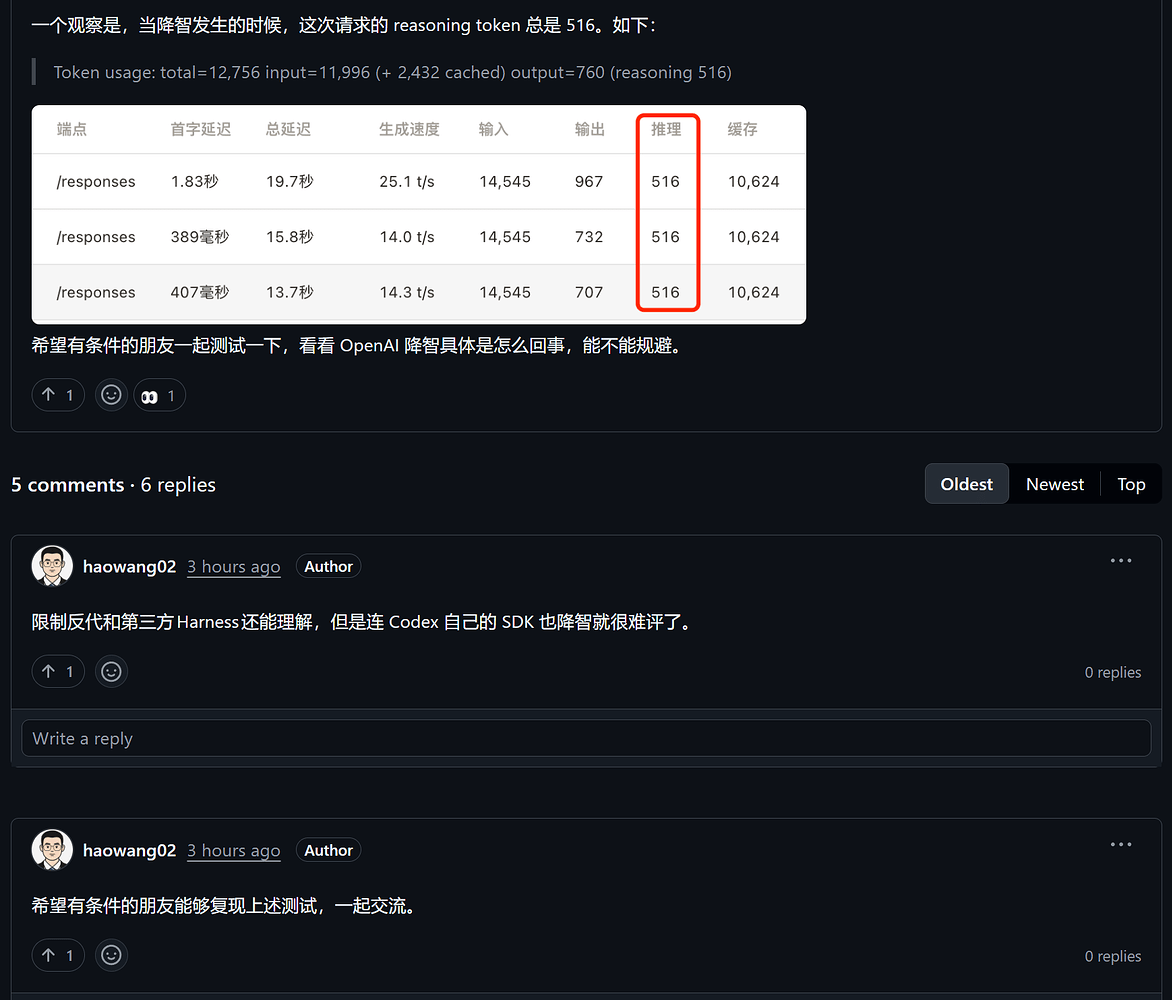
这点非常重要。
因为如果推理 token 被异常压缩,那么模型不是“不会推理”,而是:
它可能根本没有获得足够的推理预算。
换句话说,这更像是“推理预算降级”,而不只是“模型变笨”。
这是不是 OpenAI 故意限制第三方客户端?
目前还不能这么下结论。
更严谨的说法应该是:
社区测试显示,Codex 在不同调用路径下可能存在推理预算或执行策略不一致的问题。
可能原因包括:
不同客户端请求格式不同
SDK 默认参数不同
Harness 修改了 system prompt
reasoning effort 没有被正确透传
工具层封装导致请求被路由到不同策略
OpenAI 对不同调用入口存在不同安全或成本策略
第三方代理在转发时丢失了关键字段
Codex 自身 SDK / CLI 行为不一致
这些都可能导致表现差异。
所以现在最稳的判断是:
这不是“实锤故意降智”,但已经是值得认真复现和排查的异常现象。
和 AGENTS.md 那句缓解方案有什么关系?
前面社区里还有一个缓解方案:
在项目根目录的 AGENTS.md 中加入:
DO NOT send optional commentary部分测试者反馈,这句话可以缓解 Codex 降智。
为什么可能有效?
它可能不是“修复模型”,而是减少了模型进入无效解释路径的概率。
简单说:
让 Codex 少输出废话,把更多行为集中在任务执行上。
但要注意:
这只能缓解,不能根治。
如果根因是请求路径导致的 reasoning token 被压缩,那么 AGENTS.md 只能在行为层减少干扰,不能从底层恢复完整推理预算。
这件事真正值得关注的地方
我觉得这次讨论真正重要的地方,不是某个工具有没有问题。
而是它暴露了 AI Agent 时代的一个新风险:
同一个模型,在不同调用路径下,可能不是同一种能力。
过去我们只看:
模型名称
参数规模
推理等级
benchmark 分数
但现在还要看:
你是从哪个客户端调用
请求字段有没有完整传递
system prompt 是否被污染
reasoning effort 是否真实生效
Harness 是否改变了执行行为
中间代理是否修改了请求
这意味着:
AI 工程不再只是调用模型,而是验证整条调用链。
网络安全视角:这其实是供应链问题
从安全角度看,Codex / OpenCode / CLIProxyAPI / SDK / Harness 这一类工具,本质上已经形成了 AI 调用供应链。
你的请求不是简单地:
用户 → 模型
而是:
用户 → CLI / SDK → Harness → Proxy → API → 模型 → 工具执行层
只要中间任何一层修改了上下文、丢失了参数、插入了额外提示词,最终模型能力都会变化。
这就很像传统软件供应链里的依赖风险。
区别在于:
传统供应链污染的是代码。
AI 调用链污染的是:
上下文
推理预算
工具权限
执行策略
模型行为
这比普通 bug 更隐蔽。
因为表面上你看到的仍然是“同一个模型”。
我的建议
如果你也在使用 Codex 或第三方 AI Coding 工具,建议做几件事:
对同一任务分别测试原生 CLI、SDK、第三方 Harness
记录 input token、output token、reasoning token
检查 reasoning effort 是否真正生效
检查代理层是否修改 system prompt
检查 AGENTS.md 是否存在干扰规则
对关键任务不要只看最终答案,要看可复现率
对代码修改类任务,必须加测试和 diff 审查
不要默认“同名模型 = 同等能力”
尤其是企业或安全场景,不能只相信工具输出。
必须把 AI Agent 当成一个需要审计的执行系统。
最后总结
这次 Codex 降智讨论最有价值的结论不是:
“OpenAI 一定故意限制第三方客户端。”
而是:
AI Agent 的真实能力,取决于模型、客户端、Harness、代理层、系统提示词和推理预算共同组成的调用链。
一句话:
未来测试 AI,不只要测模型,还要测调用路径。
如果你只看模型名,不看请求链路,那么你看到的“智能”,很可能并不是模型真实能力,而是某条调用路径下被折叠后的结果。