如何通过Nginx配置过滤恶意流量 打造一个自己的微型防火墙
作者:FancyPig | 发布时间: | 更新时间:
相关阅读
自从更新了短信漏洞之后,很多网友也顺着这个发现了一些其他漏洞,再次向各位表示感谢!
同时,很多个人博主资金有限,没有付费的waf,那我们今天教大家拿Nginx来过滤恶意流量,免费且实用!
Nginx配置可以过滤什么?

恶意IP(黑/白名单)
首先,Nginx可以过滤恶意IP,你可以加入下面的配置,譬如恶意IP地址为8.215.34.190、42.59.101.116,那我们可以直接
location / {
deny 8.215.34.190;
deny 42.59.101.116;
}然后上面的IP就不能访问我们的/路径了(如果你想局部封禁IP,比如一些路径不让这些IP访问,则可以将/修改为指定路径,譬如/admin后台地址)
location /admin {
deny 8.215.34.190;
deny 42.59.101.116;
}同样道理,如果你的网站如果只想让特定的人访问,譬如你的好朋友,它的IP地址为218.102.244.244
我们现在只想让他访问,可以这样设置
location / {
allow 218.102.244.244;
}你可以简单把上述的场景理解为是黑、白名单,但是这样看起来并不是很舒服,那么有没有方法能够简化上面的情况,当然有!你可以在其中引入文件,譬如
include /www/wwwroot/blockip.conf然后,我们把blockip.conf文件里填上恶意IP就行了
deny 8.215.34.190;
deny 42.59.101.116;有人可能会问,我太懒了,能不能让它自动判断把日志里请求频繁的自动添加进来?
当然可以,这里主要分为2种情况:
- 实时检测
- 异步检测(定时读取日志然后添加)
我们先来讲异步检测的方式吧,我们可以创建一个脚本,这里详细步骤我们都做了注释,我们先获取www.pigsec.cn.log日志中最近5万条数据,然后过滤掉常见的爬虫,然后将请求次数超过1000的加入黑名单
下面的脚本我放在了/www/wwwroot/blockip.sh
#!/bin/bash
#取最近5w条数据
tail -n 50000 /www/wwwlogs/www.pigsec.cn.log \
#过滤需要的信息行ip等
|awk '{print $1,$12}' \
#过滤爬虫
|grep -i -v -E "google|yahoo|baidu|msnbot|FeedSky|sogou|360|bing|soso|403|admin" \
#统计
|awk '{print $1}'|sort|uniq -c|sort -rn \
#超过1000加入黑名单
|awk '{if($1>1000)print "deny "$2";"}' > /www/wwwroot/blockip.conf然后,我们可以设置计划任务,让它定时运行,你可以直接crontab -e里添加
*/30 * * * * . /etc/profile;/bin/sh /www/wwwroot/blockip.sh当然,宝塔里也可以直接添加
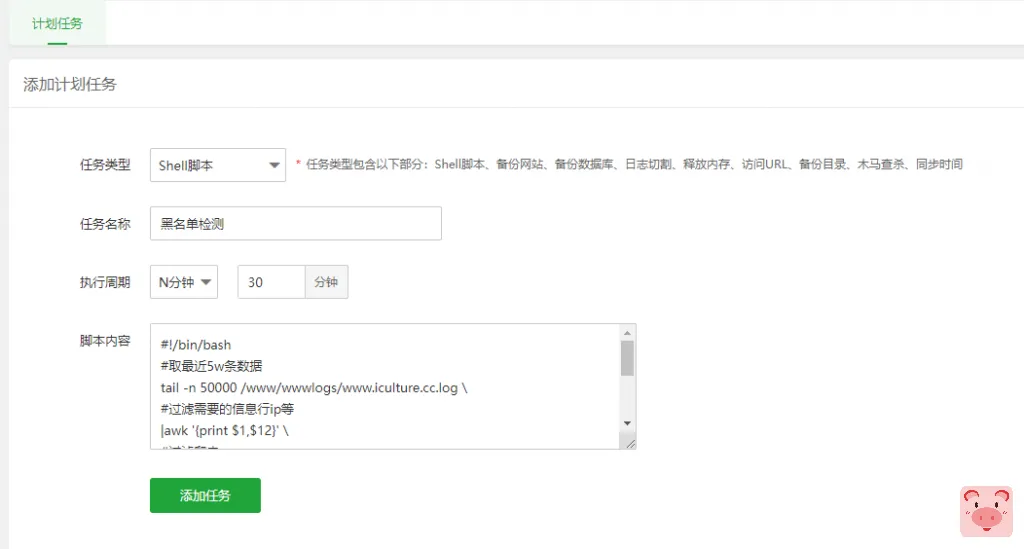
很多人会说,这样会误封怎么办,问题不大,热心网友又给大家加了脚本,我们在定期把黑名单IP注释掉,简直太秀了
#!/bin/bash
sed -i 's/^/#&/g' /usr/local/nginx/conf/
blockip.conf #把nginx封锁配置文件中的内容注释掉
service nginx reload #重置nginx服务,这样就做到了解锁IP当然,如果你想实时检测,还可以通过其他方式,详细的话我们在这期不进行介绍。
感兴趣的可以自行浏览《基于Nginx+Lua自建Web应用防火墙》
恶意请求UA
我们上次说过了,有些恶意攻击者会构造一些恶意的请求头,譬如IE浏览器的
MSIE 9.0那我们怎么去拦截呢?我们依旧可以通过Nginx配置完成拦截
if ($http_user_agent ~* MSIE 9.0) {
return 403;
}我们在这里给大家顺便科普一下,nginx里的一些配置上的细节语法,比方说,我把上面的代码改成
if ($http_user_agent ~ MSIE 9.0) {
return 403;
}代码去掉~*后面的*会发生什么?如果去掉了,表示大小写敏感,那么现在的规则可以识别MSIE 9.0但不能识别Msie 9.0或者msie 9.0了,其他的一些语法特征可以参考我们下面总结的表
| key | value |
|---|---|
| 语法: | if (条件) { ... } |
| 默认值: | — |
| 上下文: | server, location |
条件语法补充
- 变量名;如果变量值为空或者是以“
0”开始的字符串,则条件为假; - 使用“
=”和“!=”运算符比较变量和字符串; - 使用“
~”(大小写敏感)和“~*”(大小写不敏感)运算符匹配变量和正则表达式。正则表达式可以包含匹配组,匹配结果后续可以使用变量$1..$9引用。如果正则表达式中包含字符“}”或者“;”,整个表达式应该被包含在单引号或双引号的引用中。 - 使用“
-f”和“!-f”运算符检查文件是否存在; - 使用“
-d”和“!-d”运算符检查目录是否存在; - 使用“
-e”和“!-e”运算符检查文件、目录或符号链接是否存在; - 使用“
-x”和“!-x”运算符检查可执行文件;
恶意请求来路(Referer)
这里先科普一下什么是请求来路:譬如说我们从首页,点击兴趣社区按钮跳转到社区页面

这时,我们可以看到Referer字段里显示是首页的链接地址

而恶意的请求里,通常在Referer里包含接口地址(接口怎么可能是来路地址?)再或者就是明细很假的,譬如http://www.baidu.com(百度后面都不带任何参数就访问我们的网站,一看也是工具伪造的恶意流量)
那我们的规则可以设置如下,这时,我们需要将~改成=,只有Referer:https://www.baidu.com/时会返回404
if ($http_referer = "https://www.baidu.com/") {
return 404;
案例一:如何通过Nginx缓解恶意短信接口盗用
我们这里分析一下完整的请求过程,恶意攻击者先对/wp-admin/admin-ajax.php接口地址发POST请求,然后我们检测到恶意攻击者cookie是空的,没有填

但是,这时我们遇到一个问题,每个我们都能表示出来,nginx好像默认没有逻辑连接符!
我们现在需求是
if ($request_uri ~* /wp-admin/admin-ajax.php && $request_method ~* POST && $cookie_PHPSESSID = '') {
return 403;
}我们这时,可以通过设置flag来完成
#禁止空cookies请求短信接口
set $flag 0;
if ($request_uri ~* /wp-admin/admin-ajax.php) {
set $flag "${flag}1";
}
if ($request_method ~* POST) {
set $flag "${flag}1";
}
if ($cookie_PHPSESSID = '') {
set $flag "${flag}1";
}
if ($flag = '0111') {
return 403;
}整个代码的思路就是如果请求/wp-admin/admin-ajax.php接口了,flag后面加个1,默认是0,现在就是01了
如果是POST请求,flag后面再添个1,现在就是011了
最后,如果cookies中PHPSESSID为空,那么flag后面再添1,那么现在就是0111了,如果flag为0111时,那么这时禁止访问。这个方法看起来是不是也很不错呢!
案例二:如何通过Nginx拦截爬虫爬取特定接口
有些爬虫会爬取我们的一些接口信息,我们可以通过Nginx配置进行有效拦截
if ($http_user_agent ~* "qihoobot|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo! Slurp|Yahoo! Slurp China|YoudaoBot|Sosospider|Sogou spider|Sogou web spider|MSNBot|ia_archiver|Tomato Bot") {
return 403;
}但是上述方法会让爬虫无法正常访问网站的内容,那么如何加工一下呢?还是参考我们之前的那个逻辑,譬如我们用户信息的接口地址是/api/userinfo,那么我们不让爬虫访问这个地址就行了
#禁止爬虫爬取用户信息数据
set $flag 0;
if ($request_uri ~* /api/userinfo) {
set $flag "${flag}1";
}
if ($http_user_agent ~* "qihoobot|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo! Slurp|Yahoo! Slurp China|YoudaoBot|Sosospider|Sogou spider|Sogou web spider|MSNBot|ia_archiver|Tomato Bot") {
set $flag "${flag}1";
}
if ($flag = '011') {
return 403;
}案例三:如何通过Nginx给站点做灰度测试
比方说,我们现在想给网站里的元老级用户,让他们参与内测,那这时,如何让他们访问到内侧页面
详细方案可以参考《使用Nginx实现灰度发布》
我们这里只简单做个说明,譬如,我想让元老用户访问到隐藏页面(这里假设隐藏页面就是我的知乎)
那么,我们的要求是用户cookies里要有FANCYPIG参数,且参数里有svip,然后让他们跳转我的知乎
if ($cookie_FANCYPIG ~* svip) {
return 301 https://www.zhihu.com/people/pigsec;
}我们这里增加个cookie进来,使用的是Cookie-Editor浏览器插件(需要科学上网)

测试下再访问首页居然可以跳转到知乎上了,是不是还蛮有趣的

这时,就会有热心网友想的了一个奇葩的方式,譬如有些攻击者有的时候会在header里带一些恶意的字符,在简单点说,比如,我在请求页面的时候,带了test这样的词
那么,我们让这些热心网友都去访问gov.cn去吧😂😂😂
if ($request_uri ~* test) {
return 301 http://gov.cn;
}还有很多有趣的欢迎你去研究
常见的字段,我们也给大家做了总结
| 字段名称 | 字段解释 |
| $arg_name | 请求行中的name参数 |
| $args | 请求行中参数字符串 |
| $cookie_name | 名为name的cookie值 |
| $document_uri | 同 $uri |
| $http_name | 任意请求头的值 |
| $host | “Host”请求头的值 |
| $query_string | 与$args相同 |
| $realpath_root | 按root指令或alias指令算出的当前请求的绝对路径 |
| $remote_addr | 客户端IP地址 |
| $remote_port | 客户端端口 |
| $remote_user | 为基本用户认证提供的用户名 |
| $request | 完整的原始请求行 |
| $request_body | 请求正文 |
| $request_body_file | 请求正文的临时文件名 |
| $request_completion | 请求完成时返回“OK”,否则返回空字符串 |
| $request_filename | 基于root指令或alias指令,以及请求URI,得到的当前请求的文件路径 |
| $request_method | HTTP方法,通常为“GET”或者“POST” |
| $request_time | 请求处理的时间,从客户端接收到第一个字节开始计算 |
| $request_uri | 完整的原始请求行(带参数) |
| $scheme | 请求协议类型,为“http”或“https” |
| $status | 响应状态码 |
| $uri | 当前请求规范化以后的URI |
| $content_length | “Content-Length” 请求头字段 |
| $content_type | “Content-Type” 请求头字段 |
| $limit_rate | 用于设置响应的速度限制,详见 limit_rate |